铁丝&焊盘分割
咸鱼上接的单 目的是分割出铁丝和焊盘
咸鱼上接的单 目的是分割出铁丝和焊盘
某鱼上的课设
代码来自 github 博客,原本的代码用的是背景估计的检测方法,效果不太好。将检测方法改成 opencv级联检测后,效果好了许多
解决 opencv VideoCapture 返回为 None 的问题 参考链接
1 | conda install -c menpo opencv3 |
win系统下 qt crator + opencv2.4.9配置
https://src.fedoraproject.org/rpms/opencv/blob/f24/f/opencv-2.4.12.3-gcc6.patch
为了快速准确地提取舰船目标, 目前的舰船检 测方法通常采取由粗到精的策略, 首先从大幅图像 中快速提取出候选区域, 利用反映舰船目标的最为 明显且计算量小的一些特征, 确定出舰船目标可能 存在的区域; 然后再利用精细特征对候选区域进一 步确认分析, 去除虚警, 找出真实的舰船目标
对于小于 3m的低分辨率遥感图像 ,由于分辨率较低 ,图 像中无法反映出舰船目标的细节特征 ,所以仅计算每个候选 目标进行一阶灰度特征。包括平均灰度、方差、一阶能量、 一阶熵等 )来构建目标向量。
对于高于 3m的高分辨遥感图像 ,由于图像可以反应目 标细节特征信息 ,因而在构建目标向量过程中 ,可以通过增加 灰度共生矩阵的二阶纹理特征 [16] (包括相关性、局部平稳、惯 性矩、二阶熵等 )和形状不变矩 来提高识别的精确度。
论文:基于SVM 的高分辨率SAR图像舰船目标检测算法
亮度特征
纹理特征:
峰值特征:
其他灰度特征:
1,2,4特征组合成特征向量效果最好

Hog特征
Gabor 滤波
论文:高分辨率光学遥感图像舰船目标检测关键技术研究
基于船头检测与船体轮廓定位的舰船检测算法。该算法根据船头区域在极坐标变换域上可近似为梯形形状的特点,首先在极坐标变换域上对Harris角点区域提取一系列船头形状特征,使用SVM分类器筛选出疑似船头区域,同时给出船身的初始方向;然后,借助于周围与船身方向一致的直线段对船身初始方向进行修正,可得到更加准确的船身方向,并利用船体轮廓的对称性与船体轮廓处直线段定位出船身;最后通过海洋上下文信息剔除掉虚假船只
紧致度,凸度,矩形度,偏心率,矩不变量
论文:基于支持向量机的遥感图像舰船目标识别方法_李毅
不随图像位移 旋转 尺度 变化。但是不变矩特征仅能构表现物体的整体形状特征, 而不能提 取细节分量上的特征信息 + 共生矩阵求纹理特征(这个需要尺寸较大 例如 3m分辨率以上)
简单为例特征:均值,方差,矩,熵
首先按照不变长宽比的原则将 扣出用于训练的图像块
在训练时将 图像块 resize 为 train_size,训练svm
测试的时候,输入为一张完整的图片,已知图中的目标的大小,按照 设置的 obj_size,将原图缩小,使得目标的尺寸 = obj_size
测试一:
hrsc数据集 crop 出来的原图
测试发现 obj_size = 10 检测率和虚警率都不会降低。难道是因为 这样缩放虽然目标的信息丢失了,但是背景的信息也丢失了,所以实际信噪比不变 ,检测率就不怎么改变
如果是常规小目标 输入图像是1280*720的尺寸,如果hog特征的尺寸还是设置为80x80,输入测试的时候就检测不到图上存在的10x10的小目标。
使用谷歌 api ,很方便。按照谷歌的官方文档快速开始
1 | pip install --upgrade google-api-python-client |
库 选项,进入,选择 YouTube Data API v3启用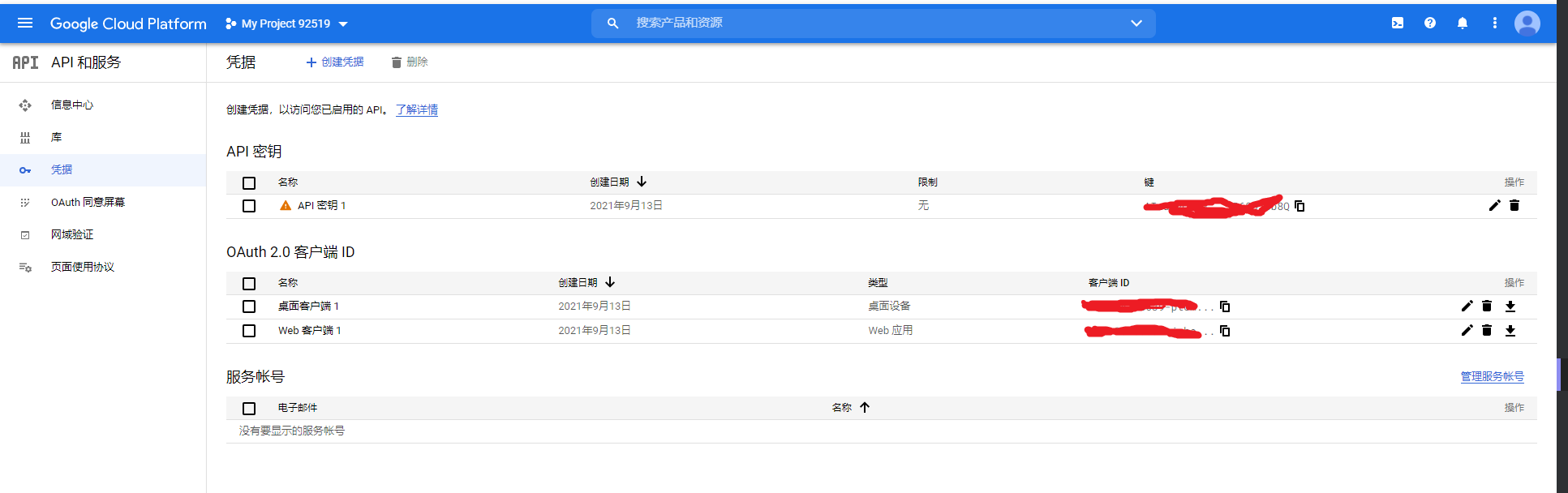
1 | import os |
pyenchantnltkgensim,TF-IDF聚类使用 TextBlob 来判断单个词的情感
首先在远程创建一个工程,按照工程下的提示在本地该工程的文件夹下打开git bash按顺序输入(其中有和远程库关联的步骤,必须输入)
git init 在当前文件夹下创建一个git 仓库管理该文件夹下的工程
git add . 表示将所有文件提交到监控区域 则有文件改动都会被记录
git commit -m "inform" 提交当前改动
git push 将代码提交到git hub 远程仓库 不要在浏览器上随意删除已经提交了的文件,否则本地的记录和云端的记录不一致再次提交会报错,所有对文件的修改最好只在本地修改让后上传云端
空文件夹不会被add添加 只有里面有文件才会被add .gitignore文件可以选择push时忽略的文件
在新的机子上生成 公钥 ssh-keygen -C“ changruowang@qq.com” 然后在用户目录下 把生成的id_rsa.pub文件中的东西粘贴添加到 网页版github账户的列表中 这样本地可以访问远程github仓库了
使用 git clone https… 形式的连接,提示错误,要将 http / https 代理关闭
fatal: unable to access 'https://github.com/hexojs/hexo-starter.git/': Failed to connect to 127.0.0.1 port 1080: Connection refused
git config --global --unset http.proxy
git config --global --unset https.proxy
2021/9 月提交一个爬虫工程很多报错,最后使用下面的流程成功新增了一个 resp 并提交
无论const修饰全局还是函数的局部变量,那么该变量都不能被程序员显式的修改,否则编译器会报错。但是变量本质都是地址,因此可以对他取地址给指针,然后通过指针再去修改该值。这样操作编译器不会报错。例如:
1 | const int N = 1000; |
c++ 对 const 会对默认类型的变量(非自定义的结构体成员变量,常规的int float 等会优化)在编译时期会优化,上面的例子中 会将所有地方的 N 像宏定义一样直接替换为 1000;例如
1 | cout << N << " " << *p; |
因此 推荐将变量定义为 const 类型 这样编译器会直接替换为值,后面就减少一次内存访问请求 相对宏定义的优势就是 有类型检查
定义 const 类对象 或者 结构体变量一样,代表他们的成员都不能被修改。并且,const 类对象只能调用它的 const 成员函数,而不能调用普通的非const成员函数。

const int *pint * const p = &a ( 就看const 后面跟的是啥 啥就不能变)代表该成员函数 不能修改类中的成员变量,同时也正是这个特性,const 类的对象只能调用 ocnst 修饰的成员函数
constexpr是C++11中新增的关键字,其语义是“常量表达式”,也就是在编译期可求值的表达式。最基础的常量表达式就是字面值或全局变量/函数的地址或sizeof等关键字返回的结果,而其它常量表达式都是由基础表达式通过各种确定的运算得到的。constexpr值可用于enum、switch、数组长度等场合。
1 | template <int N> |
constexpr 在修饰函数的时候
constexpr的好处:
求字符串的连续子串,如果传统的散列法复杂度很高。而Rabin-Karp算法的思路是 将字符串每个 字符 a~z 看作 0~25 组成的 26 进制的数。并且在计算 每个位置长度 为 n 的连续子串的散列值时 可以使用 除留余法 方式 将散列的复杂度降低为 O(1)

这个题也可以用 动态规划做,dp 设置为 字符串1 前 i 个 和 字符串2 前 j 个的子串的最长后缀长度。通过 两层遍历即可完成。
但是使用 二分查找 + hash 法 复杂度会更低(前提是 hash 使用Rabin-Karp算法散列,保证散列的复杂度为O(1))
主要就是 能划分为 二分图,集合0中的元素之间不会有匹配关系,它只会和集合1中的元素有匹配关系,可能一对一一对多。同理集合2中的元素也是
常用的套路是 按照 奇偶 位置划分二分集合。
首先 依次从左边集合中选出一个元素 和 右边集合中的元素匹配。如果右边集合中某个元素已经被占用了,那么根据它指向的左边集合中的元素号,递归的去调整它,以给当前元素腾位置。如果能腾出来,那么成功。否则返回false 算法实现的关键在于 一个记录 右边 到左边 的数组序号的映射关系,和 右边序号的访问情况。
算法时间复杂度,O(ExV) V为左边集合顶点的数目,E为图中的边数。每次去左边的一个顶点去和右边集合的顶点匹配,最坏情况就是把图中所有的边都遍历一遍才能找到可以匹配的结果。
1 | int M, N; //M, N分别表示左、右侧集合的元素数量 |
KM 算法是解决带权值的 二分匹配问题
基本原理也是依靠匈牙利算法,但是每个边都带了权重,因此思想是 取当前的最大子图 然后按照匈牙利算法去寻找完美匹配,如果无法实现完备匹配 就需要扩充最大子图。
通俗的算法原理:集合A中的1个元素都可以和B中的多个元素匹配,但是由于只能择其一,所以就选和B中匹配得分最大的边 联通,同理所有A中的点都这样筛选边,这样如果 A中的所有元素都和B中的有匹配(即实现完备匹配),那么此时图的匹配权重一定是最大。此时这就可以转化为匈牙利算法去搜索有无完备匹配。
如果没有实现完备匹配,那一定是有 n 个点 n-1 个边之间出现冲突。所以直观的应该放宽选取可匹配边的权重标准 让新的权重较小的边也加入图中,再尝试是否可以完备匹配,如果此时可以完备匹配 那么起始最终匹配的权重和相对初始的最大子图的完备匹配后的权重和(但是无法实现) 是 略微缩小的。KM算法就是通过一定的策略完成 扩充子图 -> 完备匹配 这个循环的,并保证 子图的权重 一定是 从初始最大 -> 小递减的 中间没有跳跃,所以最后匹配的权重和最大
实现子图扩充最优 要 按照两个原则来实现: