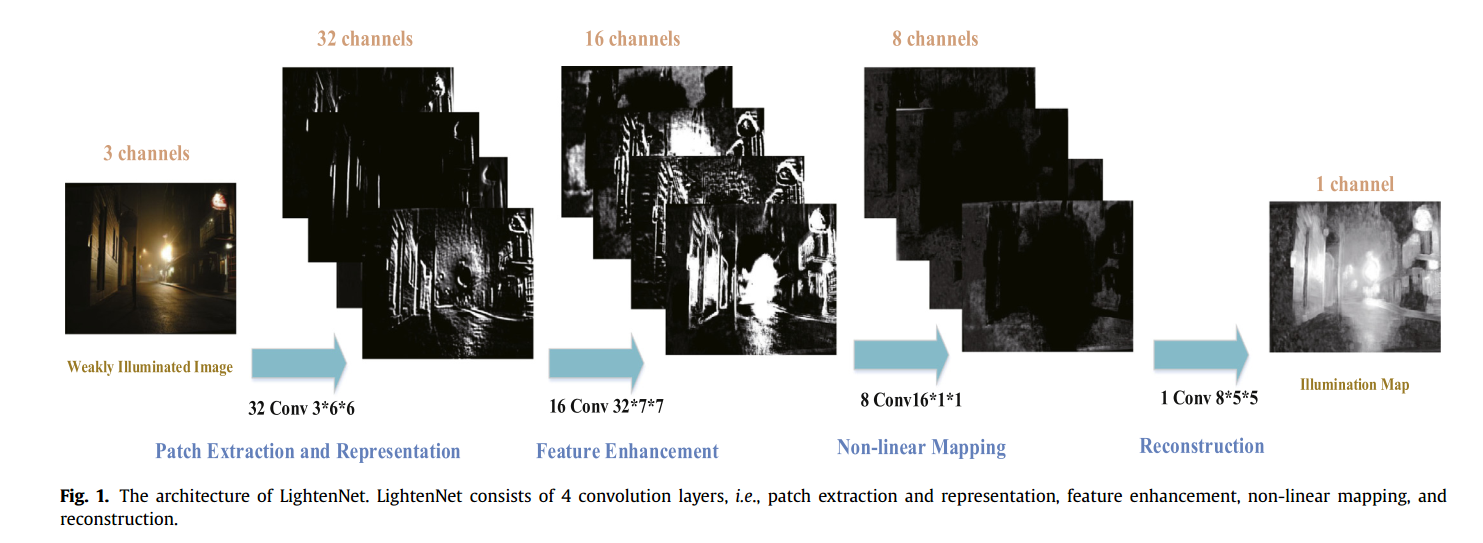
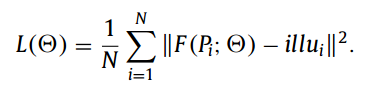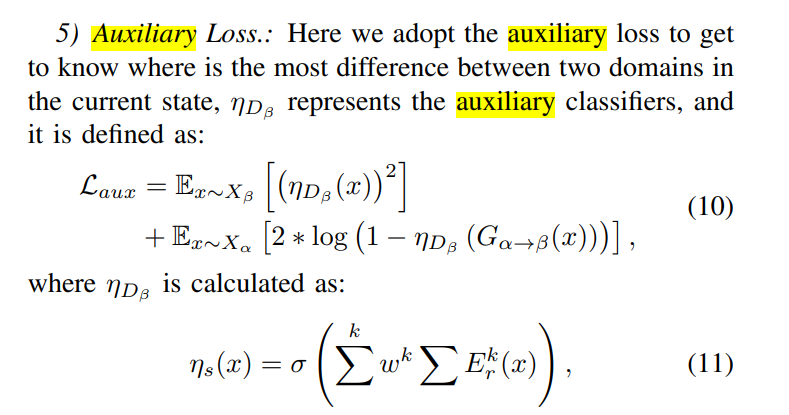\[
L_{V G G / i, j}=\frac{1}{W_{i, j} H_{i, j} C_{i, j}} \sum_{x=1}^{W_{i, j}} \sum_{z=1}^{C_{i, j}}\left\|\phi_{i, j}(E)_{x, y, z}-\phi_{i, j}(G)_{x, y, z}\right\|
\]
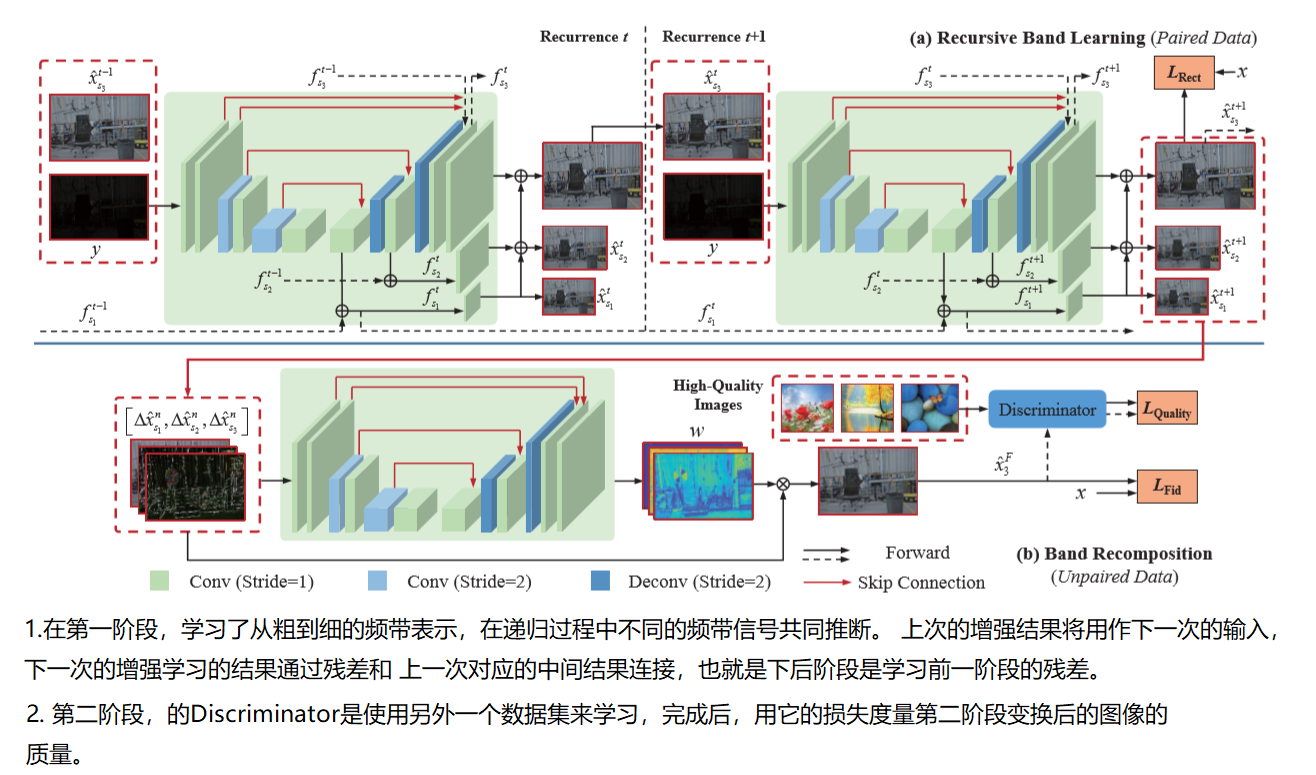
region loss 区域损失:上面两个损失函数都是基于全图的。然而在图像增强任务中,需要对低光照区域提供更多的注意力。因此作者提出这个损失函数来平衡低光照区域和其他区域的损失。作者筛选暗区域的策略是 发现选取一副图中前40%暗的像素作为暗区域最能代表实际的暗区域。这里可以寻找更恰当的选取暗区域的方法 式子中,EL GL中的L代表输入图像的暗区域,H代表亮区域 E,G代表输出图像和groundtruth WL=4 WH=1 \[
L_{R e g i o n}=w_{L} \cdot \frac{1}{m_{L} n_{L}} \sum_{i=1}^{n_{L}} \sum_{j=1}^{m_{L}}\left(\left\|E_{L}(i, j)-G_{L}(i, j)\right\|\right)+w_{H} \cdot \frac{1}{m_{H} n_{H}} \sum_{i=1}^{n_{H}} \sum_{j=1}^{m_{H}}\left(\left\|E_{H}(i, j)-G_{H}(i, j)\right\|\right)
\]
Such a method first inverts an input low-light image, and then employs an image dehazing algorithm on the inverted image, finally achieves the enhanced image by inverting the dehazed image.
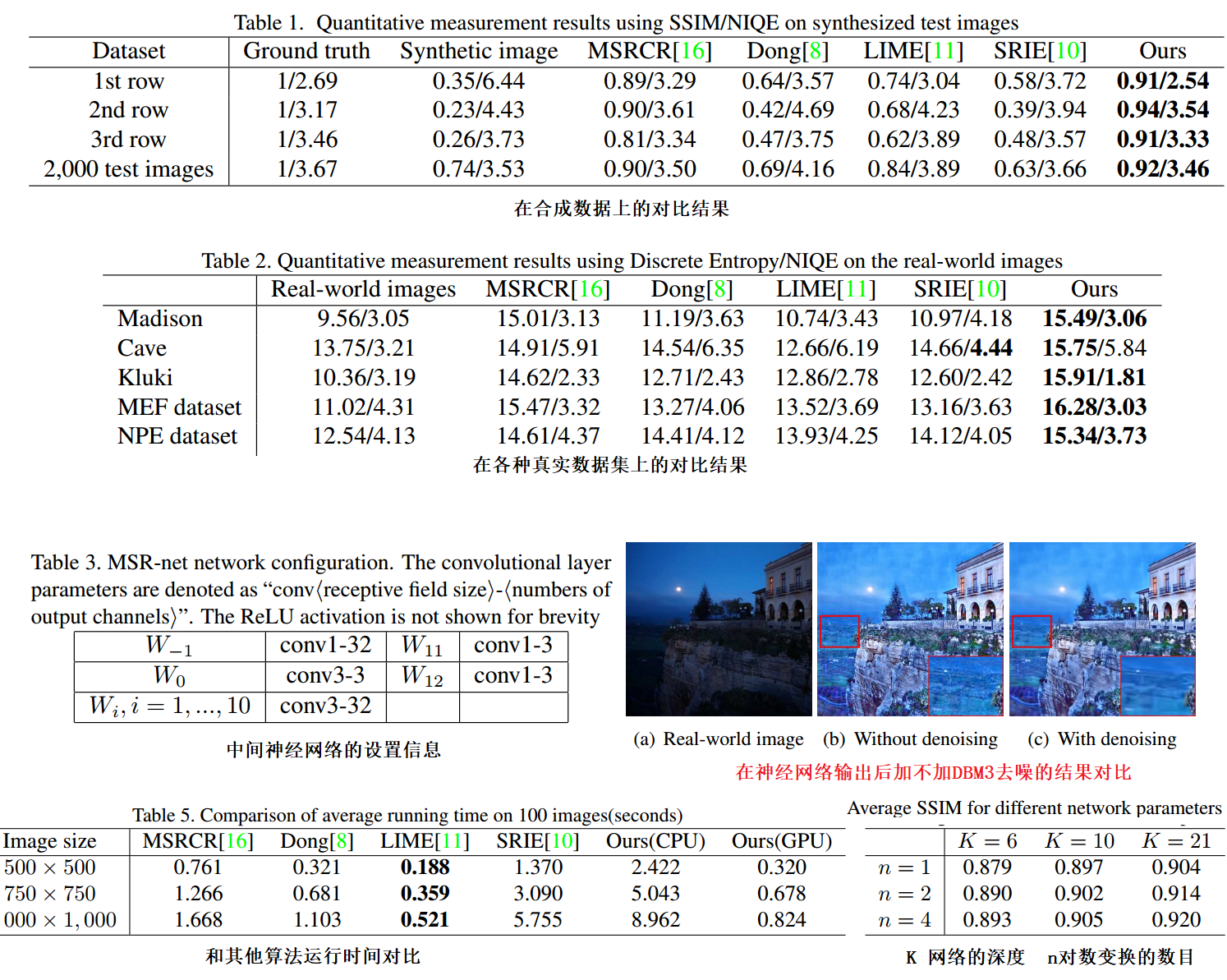
基于稀疏表示的微光图像增强框架:增强的结果在很大程度上依赖于所学习的字典的准确性 [5]
Fotiadou et al. used two dictionaries (i.e., night dictionary and day dictionary) to transform the Sparse Representation of low-light image patches to the corresponding enhanced image patches.
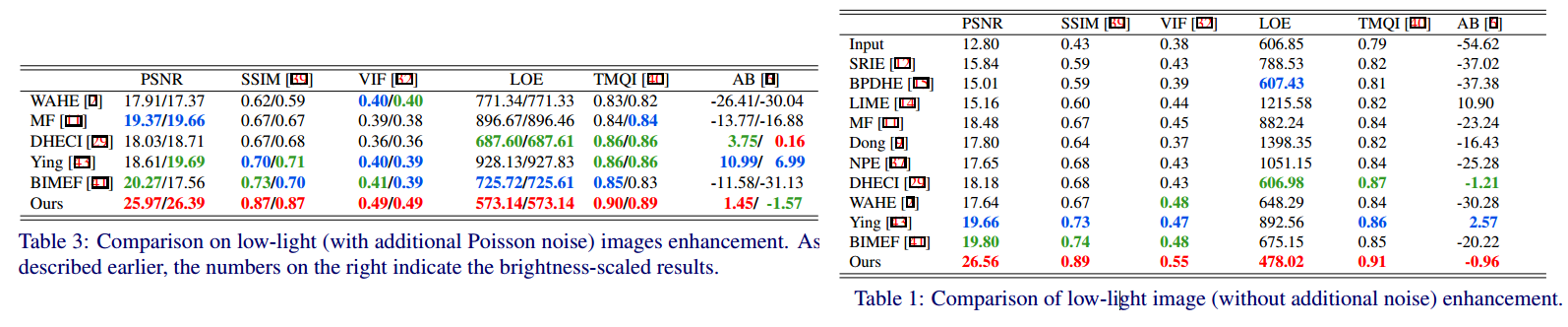
This method first estimated the illumination of each pixel in the low-light image, then refined the initial illumination map by a structure prior, finally the enhanced image was achieved based on Retinex model using the estimated illumination map. Besides, in order to reduce the amplified noise, an existing image denoising algorithm was used as post-processing in the LIME method
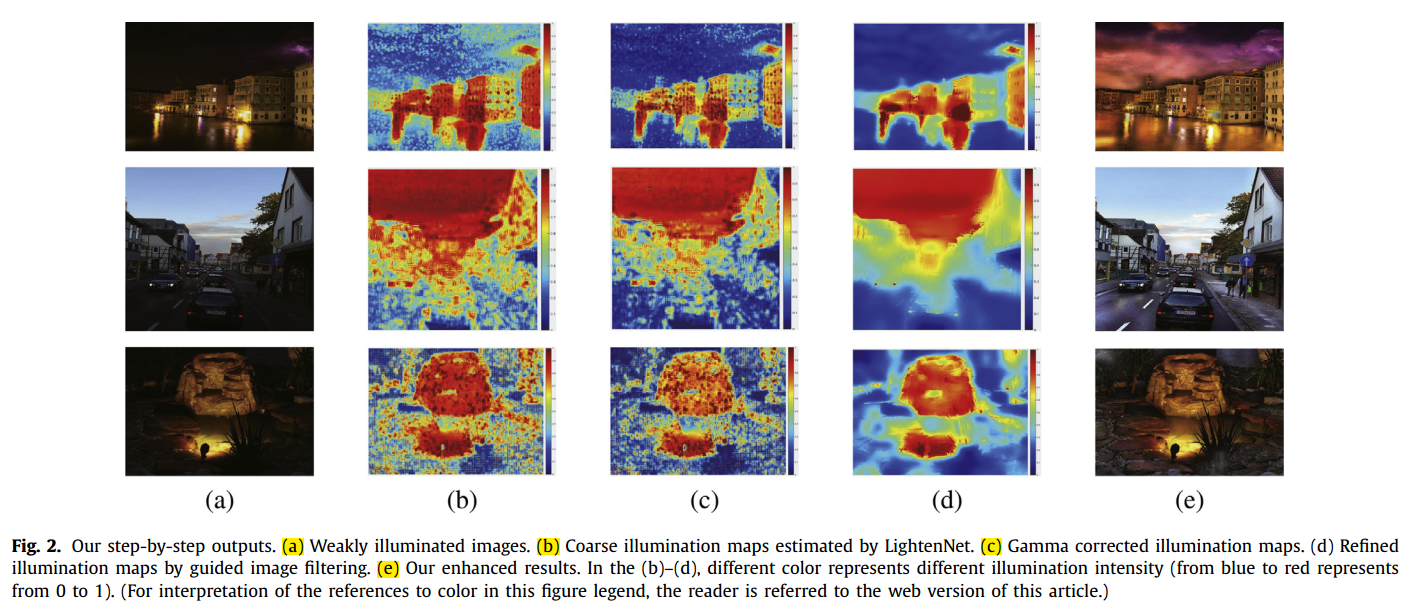
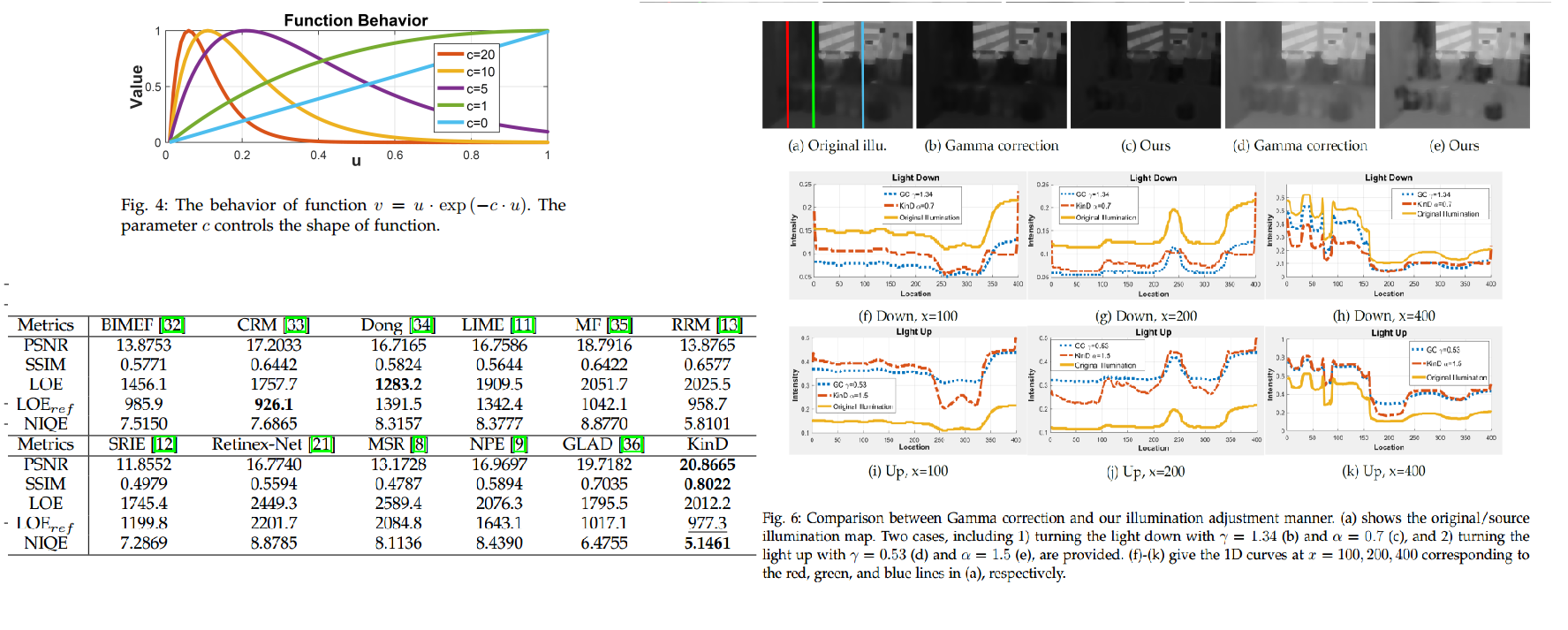
Following previous method [11], we adjust the estimated illumination map by Gamma correction in order to thoroughly unveil dark regions in the results, which can be expressed as
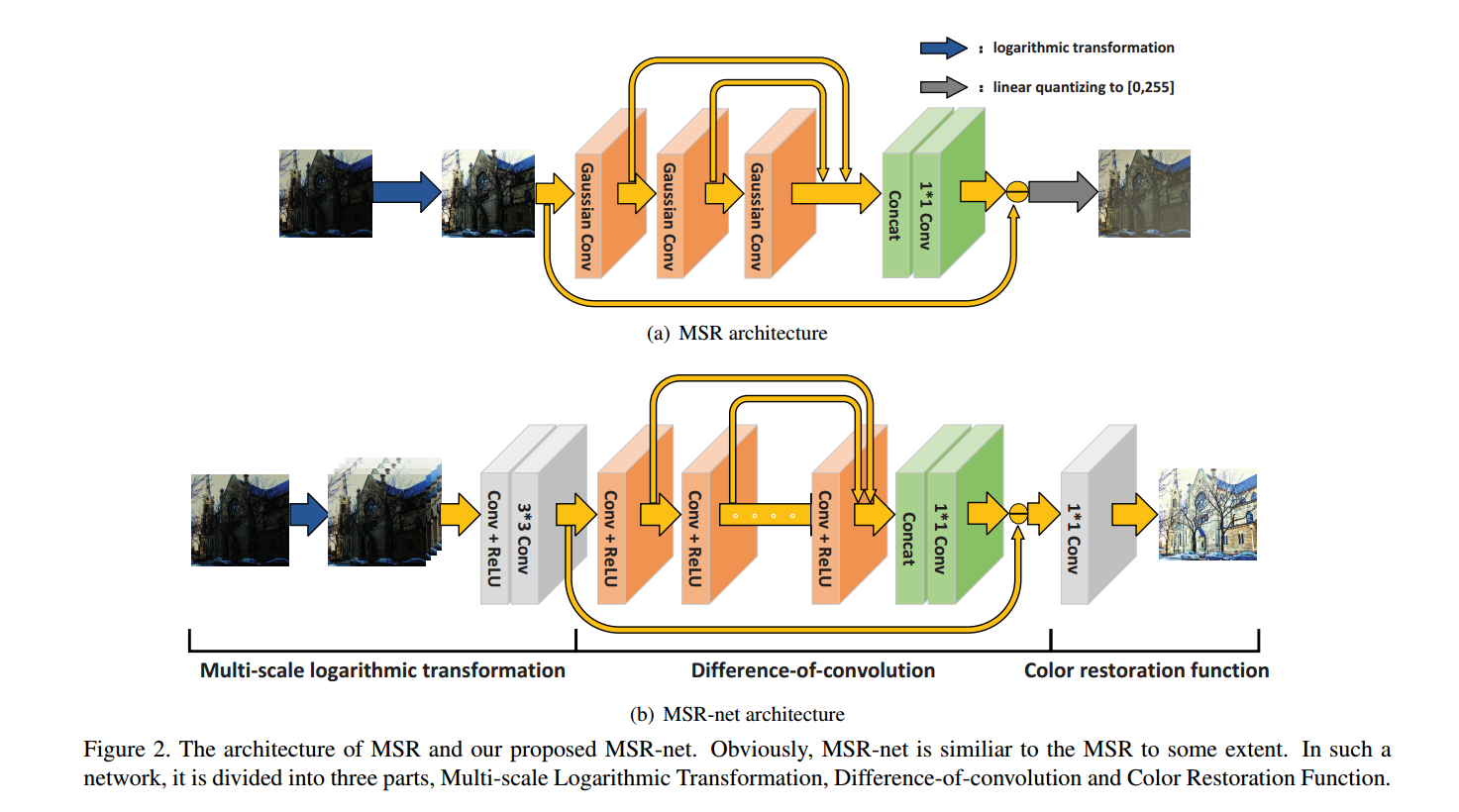
D. J. Jobson, Z. Rahman, and G. A. Woodell, “Properties and performance of a center/surround retinex,” IEEE Transactions on Image Processing, vol. 6, no. 3, pp. 451–62, 1997.
multi-scale Retinex,MSR
D. J. Jobson, Z. Rahman, and G. A. Woodell, “A multiscale retinex for bridging the gap between color images and the human ob- servation of scenes,” IEEE Transactions on Image Processing, vol. 6, no. 7, pp. 965–976, 2002.
这些方法生成的结果通常不真实,且在有的地方过度增强。
之后又有一些方法进行改进:
NPE:在增强对比度的同时保护自然光照。
D. J. Jobson, Z. Rahman, and G. A. Woodell, “A multiscale retinex for bridging the gap between color images and the human ob- servation of scenes,” IEEE Transactions on Image Processing, vol. 6, no. 7, pp. 965–976, 2002.
2.通过融合最初光照估计的多重推导来进行调整光照。
X. Fu, D. Zeng, H. Yue, Y. Liao, X. Ding, and J. Paisley, “A fusion- based enhancing method for weakly illuminated images,” Signal Processing, vol. 129, pp. 82–96, 2016
缺点:有时会牺牲真实区域的丰富纹理。
3.从初始光照图估计结构光照图。
X. Guo, Y. Li, and H. Ling, “Lime: Low-light image enhancement via illumination map estimation,” IEEE Trans Image Process, vol. 26, no. 2, pp. 982–993, 2017
缺点:假设图像是无噪声和无颜色失真的,没有考虑到退化问题
4.提出权重变分模型同时估计反射率和光照估计(SRIE),通过调整光照生成图像
X. Fu, D. Zeng, Y. Huang, X. Zhang, and X. Ding, “A weighted variational model for simultaneous reflectance and illumination estimation,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 2782–2790, 2016
5.在3的基础上提出了引入了an extra term to host noise
缺点:4、5虽然可以处理图像的弱噪声,但不擅长处理颜色的失真和强噪声。
(3)Deep Learning-based Methods
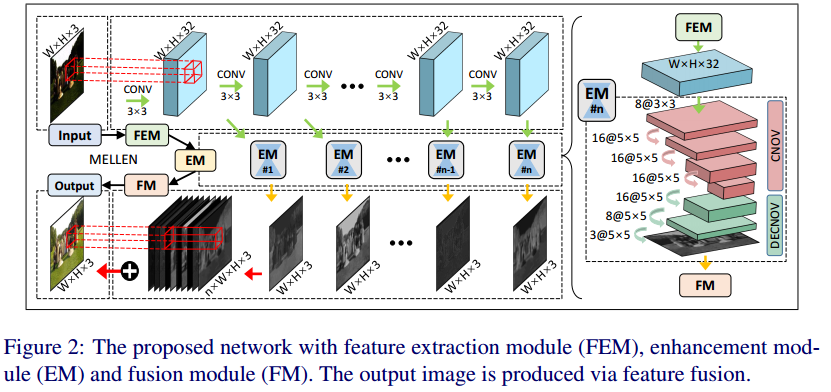
LLNet(low-light net),建立深度模型作为同时处理对比度增强和去噪的模块。
K. G. Lore, A. Akintayo, and S. Sarkar, “Llnet: A deep autoen- coder approach to natural low-light image enhancement,” Pattern Recognition, vol. 61, pp. 650–662, 2017.
C. Chen, Q. Chen, J. Xu, and V. Koltun, “Learning to see in the dark,” in IEEE Conference on Computer Vision and Pattern Recogni- tion, pp. 3291–3300, 2018.
K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Transactions on Image Processing, vol. 16, no. 8, pp. 2080–2095, 2007.
WNNM:
S. Gu, L. Zhang, W. Zuo, and X. Feng, “Weighted nuclear norm minimization with application to image denoising,” in IEEE Con- ference on Computer Vision and Pattern Recognition, pp. 2862–2869, 2014.
缺点:
由于优化具有高复杂性以及参数的搜索空间很大,这些传统方法在真实条件下效果不是很好。
基于深度学习的去噪器表现出优越性。比如:
SSDA,使用堆叠的稀疏自动编码器
F. Agostinelli, M. R. Anderson, and H. Lee, “Adaptive multi- column deep neural networks with application to robust image denoising,” in NeurIPS, 2013
J. Xie, L. Xu, and E. Chen, “Image denoising and inpainting with deep neural networks,” in NeurIPS, 2012.
Y. Chen and T. Pock, “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1256–1272, 2017.
K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142–3155, 2016.
缺点:
这些模型在blind image denoising上仍然有困难。one may train multiple models for varied levels or one model with a large number of parameters,这是很不灵活的
通过在任务汇总反复思考,这个问题得到了一定的缓解:
paper:
X. Zhang, Y. Lu, J. Liu, and B. Dong, “Dynamically unfolding recurrent restorer: A moving endpoint control method for image restoration,” in ICLR, 2018.
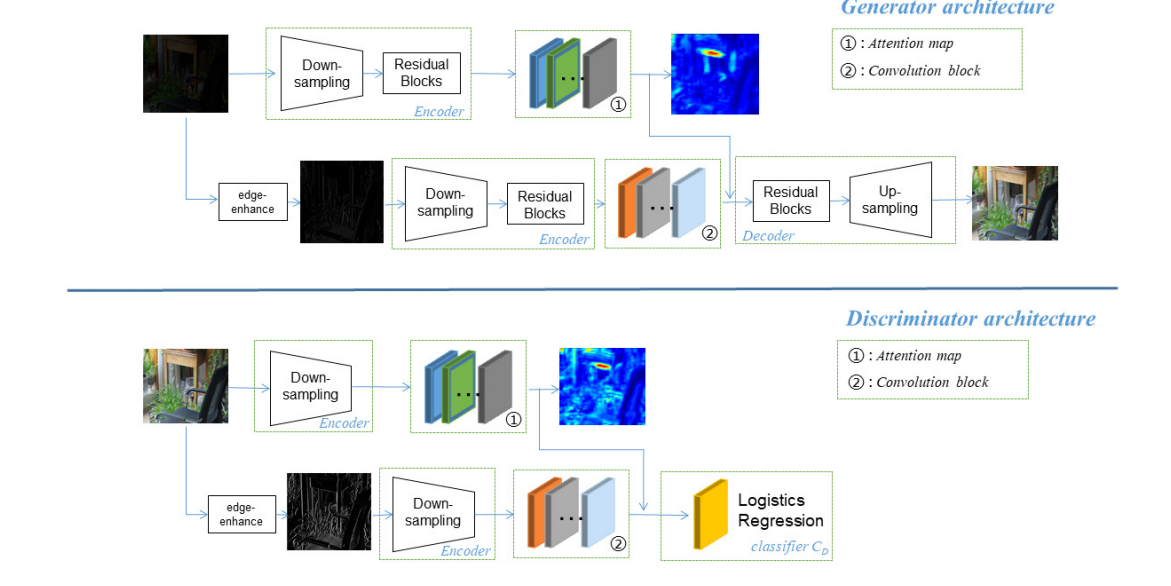
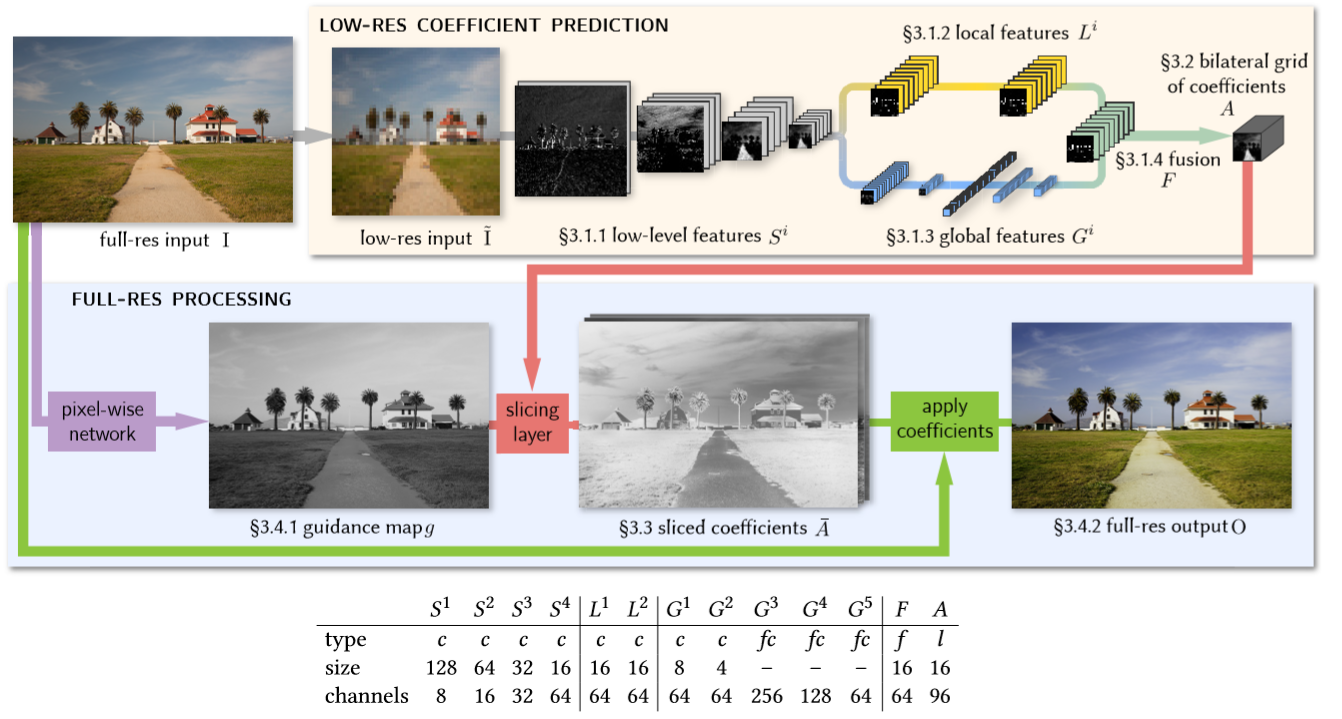
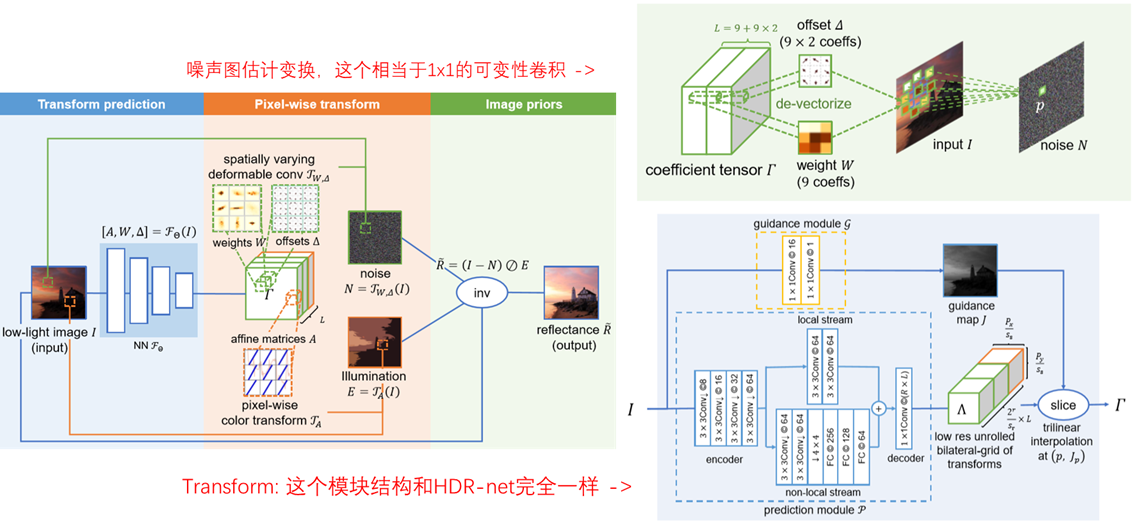
其中 \(n_{\phi}\) = 3 表示输入图像的通道数,\(\phi_{c} = I\)表示输入图像,输出的 \(\bar{A}\) 为wxhx12的变换参数 w h 代表图像原图分辨率,12 = 3x4 按照按照 [R R R b1 G G G b2 B B B b3] 的顺序排列 R R R b1意味用于计算输出图像R通道值需要用的四个参数 且 公式中的下标按照feature 的通道序号索引的。 例如输出图像的r通道的某位置的值由 r(out)(x) = [a1, a2, a3] * [r, g, b]‘(input) + instance
Stephen M Pizer, E Philip Amburn, John D Austin, Robert Cromartie, Ari Geselowitz, Trey Greer, Bart ter Haar Romeny, John B Zimmerman, and Karel Zuiderveld. Adaptive histogram equalization and its variations. Com- puter vision, graphics, and image processing, 39(3):355– 368, 1987.
Retinex
Edwin H Land. The retinex theory of color vision. Scientific american, 237(6):108–129, 1977
multi-scale Retinex model
Daniel J Jobson, Zia-ur Rahman, and Glenn A Woodell. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Transactions on Image processing, 6(7):965–976, 1997
提出针对不均匀光照用bi-log信息平衡细节与自然感的增强算法
Shuhang Wang, Jin Zheng, Hai-Miao Hu, and Bo Li. Nat- uralness preserved enhancement algorithm for non-uniform illumination images. IEEE Transactions on Image Process- ing, 22(9):3538–3548, 2013
提出加权变分模型,估计reflectance和illumination
Xueyang Fu, Delu Zeng, Yue Huang, Xiao-Ping Zhang, and Xinghao Ding. A weighted variational model for simultane- ous reflectance and illumination estimation. In CVPR, pages 2782–2790, 2016
Xiaojie Guo, Yu Li, and Haibin Ling. Lime: Low-light im- age enhancement via illumination map estimation. IEEE Transactions on Image Processing, 26(2):982–993, 2017
通过分解连续图像序列来同时处理低光照和去噪
Xutong Ren, Mading Li, Wen-Huang Cheng, and Jiaying Liu. Joint enhancement and denoising method via sequen-tial decomposition. In Circuits and Systems (ISCAS), 2018 IEEE International Symposium on, pages 1–5. IEEE, 2018
Mading Li, Jiaying Liu, Wenhan Yang, Xiaoyan Sun, and Zongming Guo. Structure-revealing low-light image en- hancement via robust retinex model. IEEE Transactions on Image Processing, 27(6):2828–2841, 2018.
Deep Learning Approaches
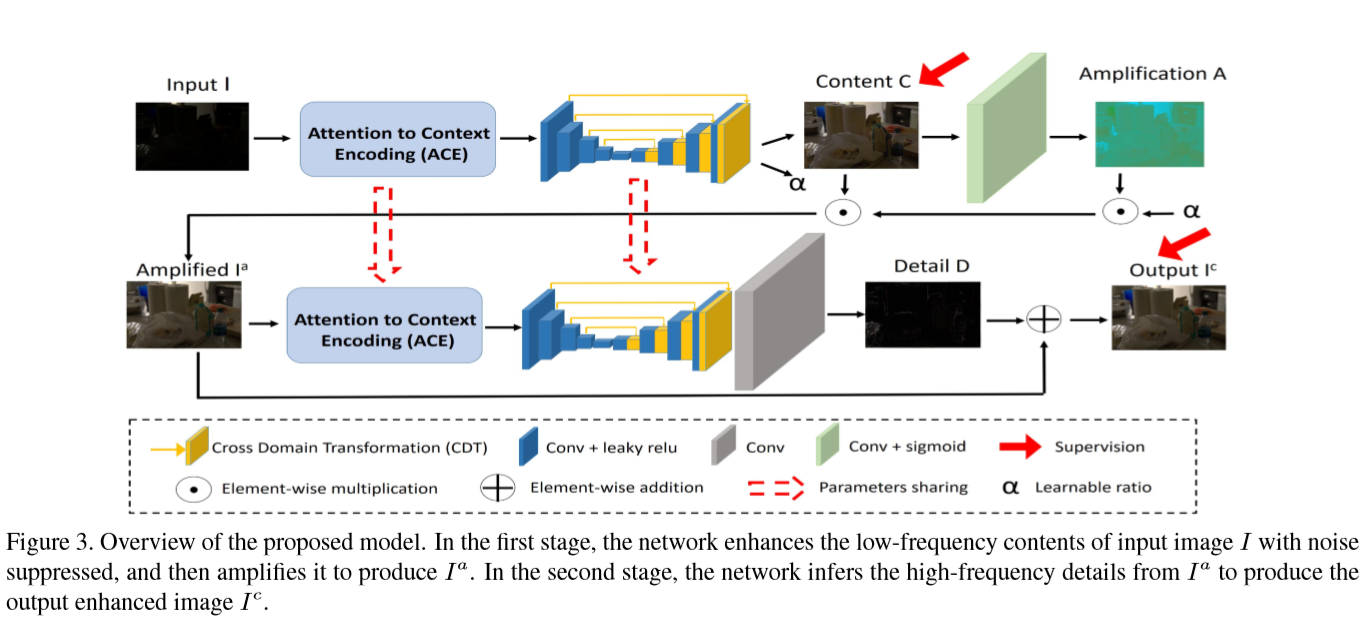
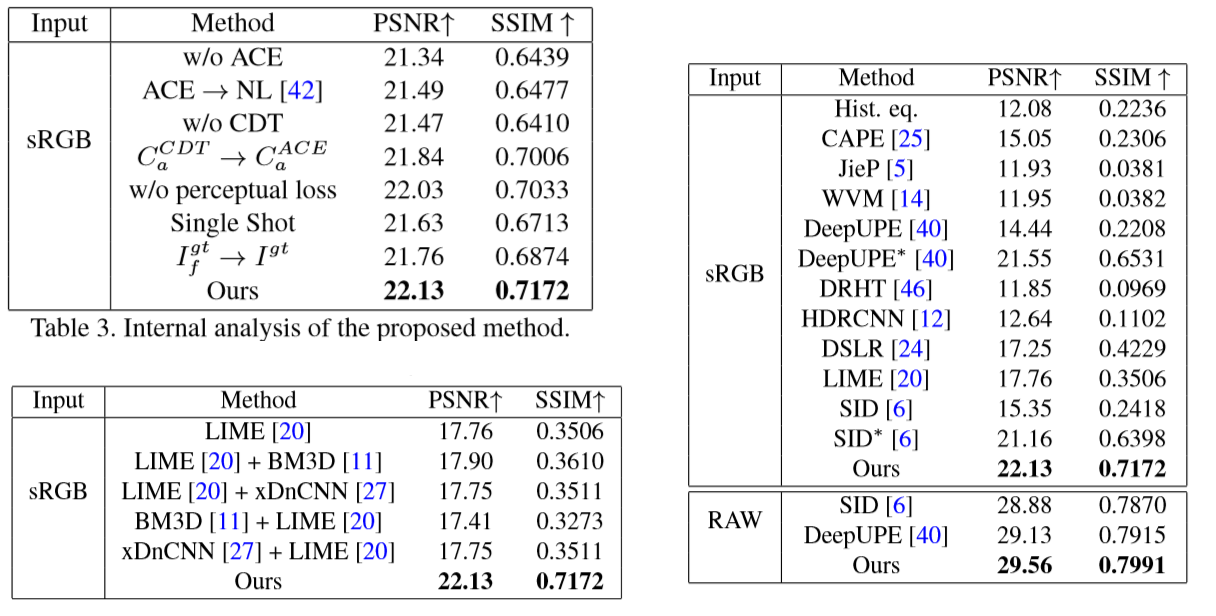
目前大部分基于DL的方法都依赖于paired image,且图像大部分是从正常图像中人工合成的。
LL-Net,堆叠的自动编码器,在patch level同时学习去噪和低光照增强。
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. Ll- net: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognition, 61:650–662, 2017.
Retinex-Net,设计了end-to-end框架,结合了Retinex理论
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018.
HDR-Net ,将深度网络与双边网格处理(bilateral gird processing)、局部颜色仿射变换(local affine color transforms)
Micha¨el Gharbi, Jiawen Chen, Jonathan T Barron, SamuelW Hasinoff, and Fr´edo Durand. Deep bilateral learning for real- time image enhancement. ACM Transactions on Graphics (TOG), 36(4):118, 2017
以及一些针对HDR领域的多帧低光照增强方法
Nima Khademi Kalantari and Ravi Ramamoorthi. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph, 36(4):144, 2017.
ShangzheWu, Jiarui Xu, Yu-Wing Tai, and Chi-Keung Tang. Deep high dynamic range imaging with large foreground motions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 117–132, 2018.
Jianrui Cai, Shuhang Gu, and Lei Zhang. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Transactions on Image Processing, 27(4):2049–2062, 2018.
learning to see in the dark,直接在raw数据上,更注重避开放大的artifacts
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. In ICCV, pages 2223–2232, 2017.
Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In Advances in Neural Information Processing Systems, pages 700–708, 2017.
Xitong Yang, Zheng Xu, and Jiebo Luo. Towards percep tual image dehazing by physics-based disentanglement and adversarial training. In The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), 2018.
Yu-Sheng Chen, Yu-Ching Wang, Man-Hsin Kao, and Yung- Yu Chuang. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6306–6314, 2018.
Xin Jin, Zhibo Chen, Jianxin Lin, Zhikai Chen, and Wei Zhou. Unsupervised single image deraining with self- supervised constraints. arXiv preprint arXiv:1811.08575, 2018.
paper:Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision, pages 694–711. Springer, 2016.
1、Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. In ICCV, pages 2223–2232, 2017.
2、Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In Advances in Neural Information Processing Systems, pages 700–708, 2017
3、Alexia Jolicoeur-Martineau. The relativistic discriminator: a key element missing from standard gan. arXiv preprint arXiv:1807.00734, 2018.