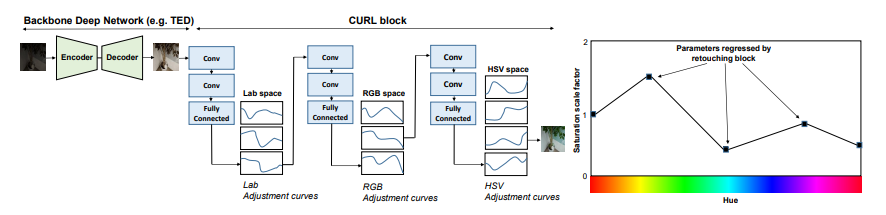
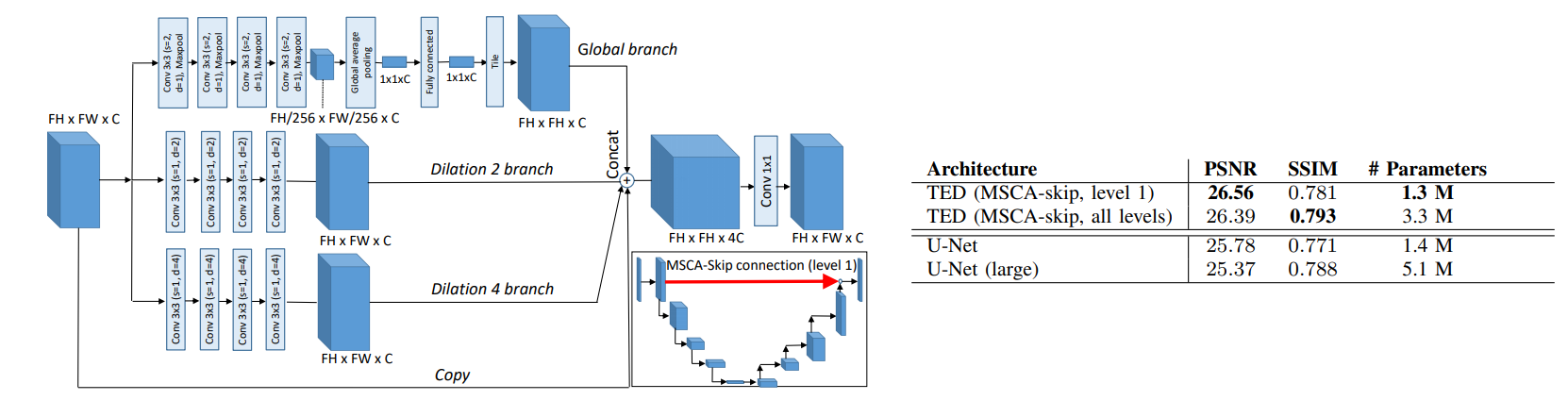
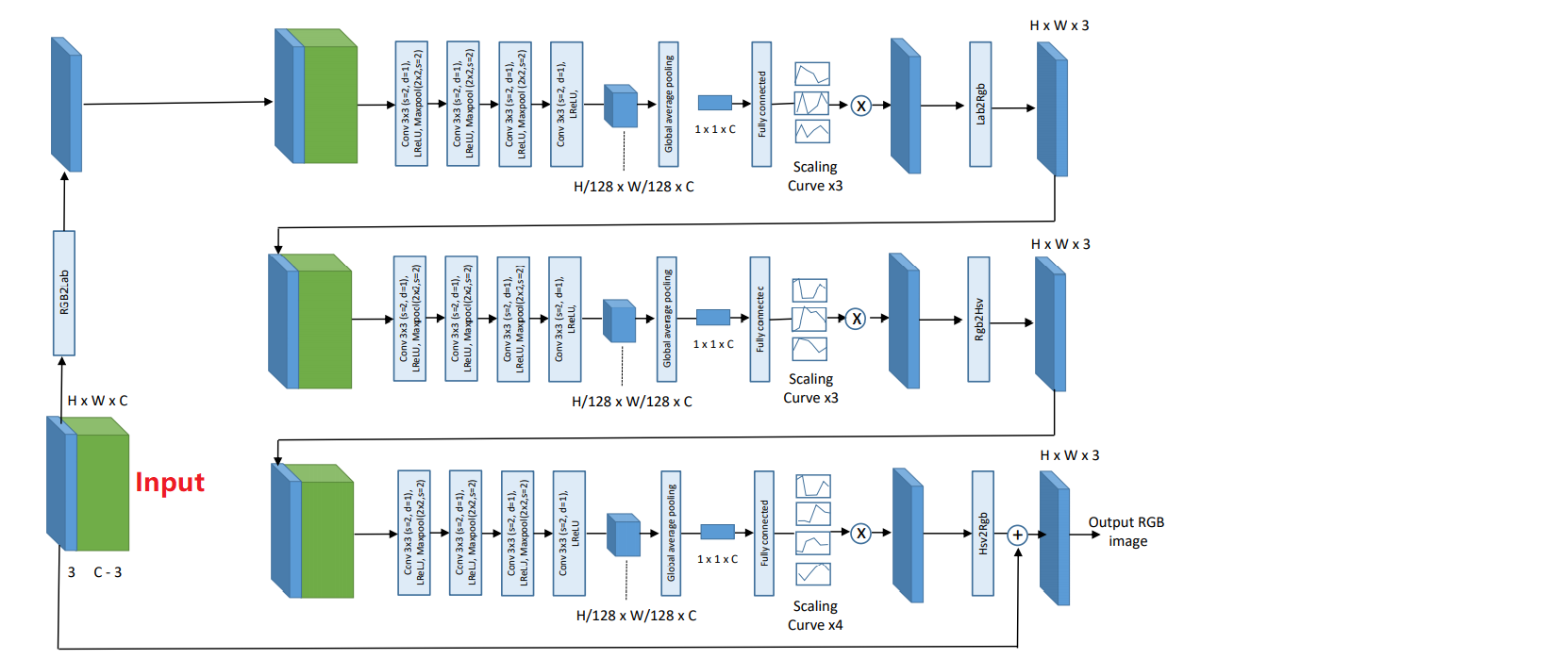
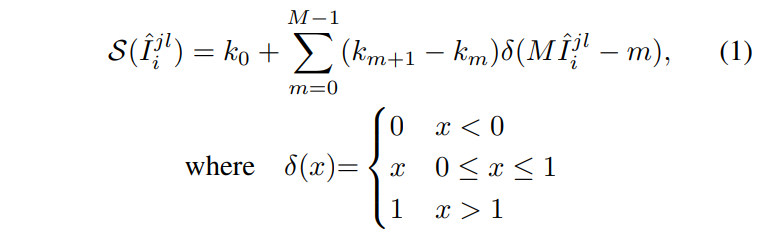Deep Retinex Net
主要贡献
- 建立了一个 采集与真实场景的 含有成对的低光照/正常光照的大尺度数据集(包含了合成和非合成的图像)
- 提出了一个基于retinex理论的图像分解的深度神经网络模型。这个模型是端到端训练的。
- 提出了用于学习图像分解模型的结构加权总变分损失。能够较好的平滑光照图同时保留原本的结构
网络结构
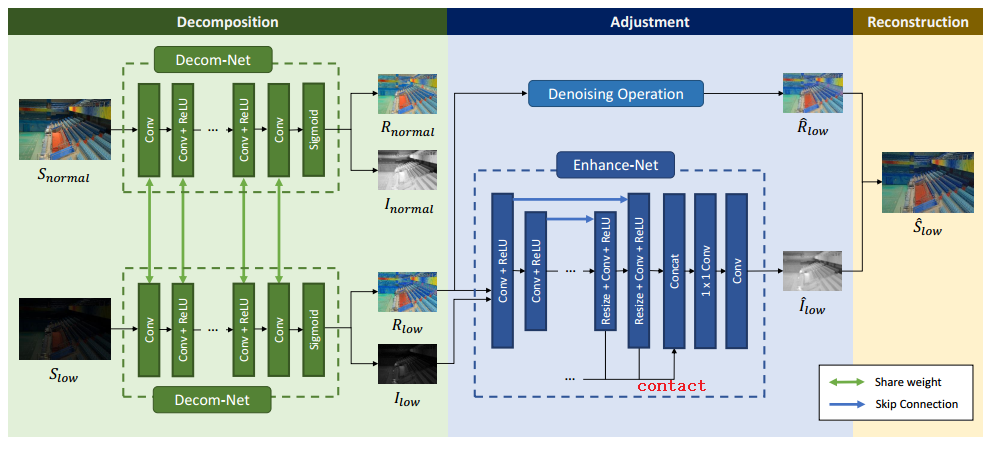
可以看出,整个模型由序列的两部分组成,图像分解,和 去噪以及亮度多尺度调整
数据驱动的图像分解 Decom-Net
这一部分将输入图像 S 分解为光照估计 I 和反射分量 R。一种分解反射和光照的方法是使用人工约束条件。然而根据retinex模型的那个式子很难实现,作者使用数据驱动的方式构建一个 Decom-Net来完成。这个网络的特点是损失函数的设计。由上图看出DecomNet的训练不需要低光照图的R和L来直接构建损失,而是通过以下几个约束条件来间接构建损失函数。
低光照图的反射率图和正常光照的反射率图应该尽可能一样: \[ \mathcal{L}_{i r}=\left\|R_{l o w}-R_{n o r m a l}\right\|_{1} \]
应该可以根据R, I 还原重建出 I 对应的 S图 。假设Sn Sl分别为输入正常光照和低光照图像, Il In为分解产生的高低光照图 Rn Rl 为分解产生的对应的反射率。约束1可知Rn应该尽可能接近Rl。 约束2的意思则是: 使用Rn Il 可以还原出Sl 使用Rn In可以还原出Sn 使用Rl Il可以还原出Sl 使用Rl In可以还原出Sn 。 R*I 即根据Retinex理论重建的过程,而-则来度量还原的程度。
\[ \mathcal{L}_{\text {recon}}=\sum_{i=l o w, n o r m a l} \sum_{j=l o w, n o r m a l} \lambda_{i j}\left\|R_{i} \circ I_{j}-S_{j}\right\|_{1} \]
- 结构平滑损失。即分解产生的光照图应该尽可能的平滑,因为认为一张图上的光照在各个区域是一致的。全变分(TV)损失,最小化整张图的梯度,通常在图像重建中作为先验平滑图像。但是直接应用TV损失来约束平滑光照图会在 图像本身梯度较大的区域失效 (下图黑边)。这是由于不管区域是纹理细节还是强边界,光照梯度都是均匀减少的。因此原本的TV损失对图像的结构是盲目的,如果在图像边缘进行强烈的模糊虽然产生的光照图会平滑但是反射率图会产生黑边。如下图。因此根据对应位置的反射率对光照梯度加上权重。上式 \(\nabla I_{i}\) 表示微光图/正常光照图的梯度,一般的TV损失是直接对全图\(\nabla I\) 求和作为损失来优化平滑图像。这里相当于根据反射率图像的梯度给梯度加上了一个权值exp()。在反射率图本身梯度大的地方权值小,小的地方权值大。作者认为在物理结构存在梯度的地方光照应该不连续 ??
\[ \mathcal{L}_{i s}=\sum_{i=l o w, n o r m a l}\left\|\nabla I_{i} \circ \exp \left(-\lambda_{g} \nabla R_{i}\right)\right\| \]
- 将上述三部分损失相加即为Decom-Net 采用的损失 \[ \mathcal{L}=\mathcal{L}_{\text {recon}}+\lambda_{i r} \mathcal{L}_{i r}+\lambda_{i s} \mathcal{L}_{i s} \] 作者还提到 关于LIME网络也在计算光照图像时考虑到图像原本的结构,但是本质和自己的不同....
For LIME, the total variation constraint is weighted by an initial illumination map, which is the maximum intensity of each pixel in R, G and B channels. Our structure-aware smoothness loss instead is weighted by reflectance. The static initial estimation used in LIME may not depict the image structure as well as reflectance does, since reflectance is assumed as the physical property of an image.

多尺度光照调节 adjustment
这个adujust网络的结构类似于U-net 的编码解码结构。降采样块包含步长为2的卷积层,上采样块使用resize-convolution层,即先将特征图插值的方法上采样然后使用步长为1的卷积和激活。这一部分的损失即为调整过后的光照图和去噪过后的反射率图重建产生的图像和正常光照图像之间的l1损失。 可以看到,在这一部分还对反射率图进行了去噪处理,使用的时DMB3
数据集
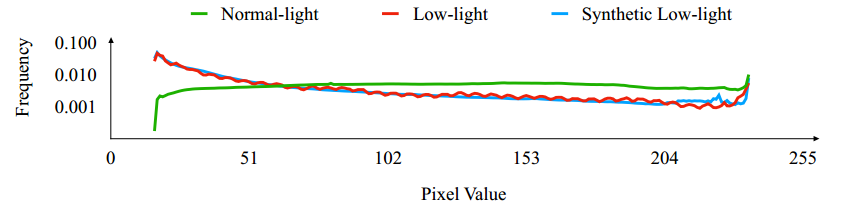
作者提出了一套数据集,包含两部分:成对的合成数据和真实的低光照图。由于真实场景的图像采集正常光照和低光照时会产生错位,作者采用了三步法来矫正。 合成图像,作者分析了已有的真实低光照图像和真实的正常图像光照的YCbCr中Y的分量,统计Y分量的直方图,根据他们的规律来合成低光照图像。
结果
本论文作者并没有贴出指标的定量分析,只是贴了几幅图。图像分解的方法是否有效有待考虑.... 定性分析:
首先作者为了证明图像分解网络设计的有效性,贴出了和LIME分别对微光图和正常图像分解产生的R , I图,发现LIME在同一个图的低光和正常光图分解的R结果并不一致, 而R反应的应该是物体本身的折射率,在低/正常图下应该一样。
同样的,在R图中 由于去掉了光照分量,应该不存在阴影,而LIME的R中存在明显的阴影,但是RetinexNet除了有噪 声外是没有阴影的 说明光照分量取出的比较彻底。
文章所提的方法不会对局部区域过曝,主要是全局光照调节效果好
得益于加权TV损失,相对于基于DeHz去雾方法 结果中没有黑边
又对比了同样含有去噪方法的JED 网络,LIME(网络后去噪) 结果,发现Retinex的边缘细节得到较好的保留。

感觉这种方法处理的结果