c++测试文件:
1 | //#include <torch/script.h> |
同目录下的 setup.py文件
1 | from setuptools import setup |
测试文件
1 | import extend_gray |
遇到提示 .so 库找不到 使用 find 命令在环境中搜,然后 添加到 LD_LIBRARY_PATH 变量中 写入 .bashrc 文件后面
1 | //#include <torch/script.h> |
1 | from setuptools import setup |
1 | import extend_gray |
遇到提示 .so 库找不到 使用 find 命令在环境中搜,然后 添加到 LD_LIBRARY_PATH 变量中 写入 .bashrc 文件后面

在定义一个方法时,使用*表示输入参数列表不确定。会将输入的参数放入一个元组中,函数内可通过访问元组的方法访问里面的数据。使用**arg也可以表示不确定参数列表,但是会将输入参数打包为字典结构。因此函数内部可以通过访问字典结构的方法访问输入参数
1 | def myprint(*arg) |
1 | def myprint(**arg) |
与上述过程相反
1 | def add(x,y): |
一般来说,将数字、字符串、元组是不可变对象,传入函数,相当于对内存进行了拷贝,在函数内修改其值不会改变函数外的值。但是对于列表、字典等可以增删的数据结构,传入函数后,相当于传递进去的是c语言中的指向地址的指针。所以在函数内对其进行有关地址的操作都可以修改函数外的变量的值。
参考链接:https://blog.csdn.net/qq_41987033/article/details/81675514
对于pytorch1.0 torch.utils.tensorboard中有这个文件,但是直接在程序中导入会报错,不考虑这个,自行安装tensorboardX。 需要安装tensorboardX为python代码执行,实现pytorch到tensorflow的转化生成一个日志文件,还需要安装tensorflow,才能调用tensorboard命令解析日志文件并上传到浏览器
1
2pip install tensorboardX
pip install tensorflow #安装的gpu版本
在程序调用一下api确保生成日志文件
1 | writer = SummaryWriter('runs/fashion_mnist_experiment_1') |
在系统命令行输入以下命令
1 | tensorboard --logdir runs |
上述的runs为刚才在py中生成日志文件的路径,得确保该路径下存放得有生成得日志文件 输入上述命令后,会产生如下输出,在google浏览器打开http://DESKTOP-F3BBIIO:6006 如果浏览被拒,改为 http://localhost:6006。如果是本机电脑链接远程服务器,则将服务器名字改为服务器的ip地址
相同: cat, stack 输入都为 1. tensor列表,2.另一个参数是维度 (n为输入tensor的维度数)
假设图像的成像模型为加性噪声,变分去噪模型包含两项,一项是数据保真项,一项是图像的全变分,即图像的梯度。两项都是无约束凸优化问题。由于噪声区域通常都是梯度异常的区域,因此TV项用在去噪中的作用就是保持图像的光滑性,但是也会对图像的细节丢失。
相对对传统邻域滤波方法的一种改进滤波,考虑到了图像的自相似性质,它充分利用了图像中的冗余信息,在去噪的同时能够最大程度的保持图像的细节特征。
借鉴了 非局部 均值滤波中的思想,原始的 变分损失就是度量的当前像素和领域像素的差值,即梯度,作为约束,期望平滑。在非局部变分损失中,将梯度重新定义为其领域一个像素与当前像素之间的差值,权重为以二者像素中心的patch之间的相似度。然后使用 split Bregman算法来求解非局部TV模型
在NLTV去噪算法中,度量像素之间的相似性是根据初始噪声图像计算的,没有考虑到算法迭代过程中像素之间的相似性,由于在迭代过程中,像素之间的相似性可能会改变,若一直利用初始噪声的相似权重可能会不准确。因此在计算像素之间的相似性时同时利用初始噪声图像的相似性和迭代过程中像素之间的相似性来计算,以增强度量像素相似性的准确性。
总的来说,就是每次迭代求解过程中 都更新一下权重矩阵,原始的非局部变分损失中的 权重 计算的是原始噪声图像的各个patch之间的相似性,双噪声相似性算法中 在权重中额外添加了一个 当前迭代结果的像素间的相似性作为参考。
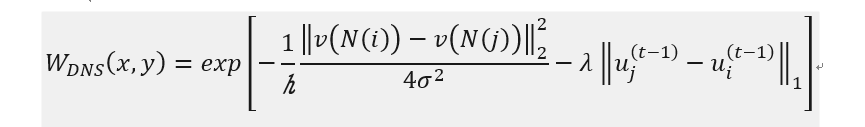
详细阅读了别人项目中的图像预处理pip line 的工程实现,使用到了多缓冲,多线程等知识点。
工厂方法是一种创建型设计模式,是基于简单工厂的改进
简单工厂是一种创建型设计模式,在创建一个对象时不向客户暴露内部细节,并提供一个创建对象的通用接口。
C++volatile关键字
单例模式是一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。
网上大佬用 C++11 写的线程池代码,和自己的阅读笔记