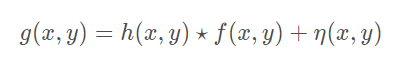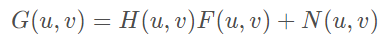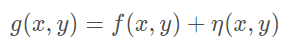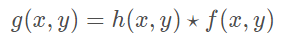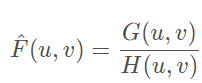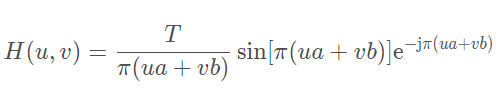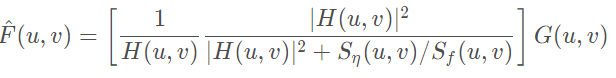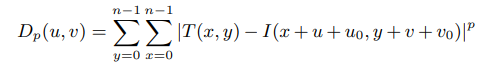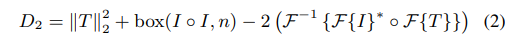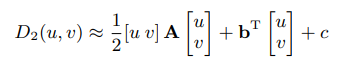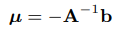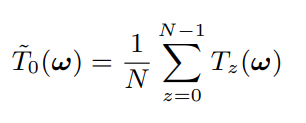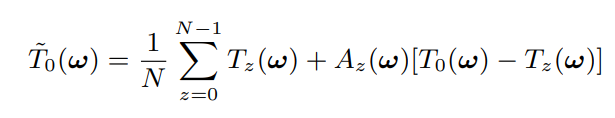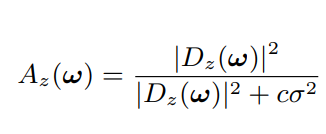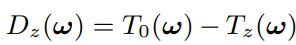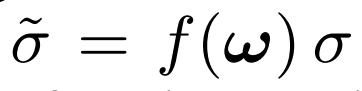HDR+
Burst photography for high dynamic range and low-light imaging on mobile cameras
参考链接
主要思想
不使用多曝光。而是使用一个固定的较低的曝光时间和增益采集多帧图像。将这个曝光设置的足够低以比避免过曝溢出
直接对bayer格式的数据处理,而不是RGB。一方面采集多帧如果都用RGB格式那每张都要经过ISP,另一方面ISP会对RAW图像做个非线性化,使得去噪变得困难
使用了基于 FFT 的快速对齐算法
主要思想是,首先使用多帧低照度的 raw 格式的图像做去噪融合成一张(这是一个常用多帧去噪手段),然后使用一个自适应的曝光算法将该图像扩展到长短曝光后融合,最后将处理后的 RAW 数据 经过ISP流程得到结果。
主要内容
故意曝光不足避免过曝而不可逆
采集多帧用于抑制暗区域噪声
使用自动曝光算法 设置长短曝光参数,短曝光参数用于调整相机硬件参数来采集固定曝光的图像,长曝光参数用于对短曝光图像做tone map合成长曝光图
使用 像素级的 曝光融合方法 融合长短曝光图像
色调映射(tone map)压缩动态范围
自动曝光
这一步其实是在多帧去噪融合之后使用的,按照原文顺序先介绍了。
现在的 ISP 中都集成了 自动对焦 自动曝光 自动白平衡算法(3A),理论上我们可以直接使用ISP中自带的自动曝光算法根据场景自动设置相机曝光参数,然后再沿用这个参数采集多帧固定曝光的图像用于后续的融合去噪。但是,对于高动态范围的场景,拍摄的图像可能包含无法通过后期 HDR 色调映射恢复的高光或曝光不足的区域。(个人感觉主要是过曝不可逆,所以要避免)
因此其实最终是对 两张gamma矫正后的图像做融合,其中一个是多帧去噪后的欠曝光图,另一张是对欠曝光后的图使用数字曝光补偿后的图。因此自动曝光算法可以 表述 为两个曝光水平:
合成长曝光 :由短曝光图合成的长曝光图,在色调映射中用于恢复阴影区域短曝光 :用于捕捉场景中亮的区域
动态范围 : 图像能捕捉的场景中的光亮度的范围。自然场景中的动态场景通常特别高,人眼能看到的范围也很大。而通常相机能表示的范围只有256中。即便相机能采集到大动态范围的图像,但是一般的显示器能显示的亮度等级也有限,一方面为了弥补相机自生的动态感知范围不足的问题常常采用多曝光融合的方式来合成高动态的图像(场景亮暗细节都能保留),另一方面还要通过tone map色调映射技术将HDR图像压缩为,转换成可以在显示器上显示出更符合人眼视觉的LDR图像。动态范围
虽然说要尽量先使用低曝光的图像去采集多帧图像,从而避免饱和。但是曝光太低意味着噪声太强,需要融合更多帧来抑制噪声,这需要付出计算代价。同时如果过分的压缩动态范围(我理解为这是 Tone map 这一步的压缩动态范围,将合成的高动态图使用色调映射手段压缩为显示器可以显示的范围)会出现卡通效应(就是阴影部分被过度提亮了)文章中设置的压缩比为8(即最亮:最暗大约8比1)
基于实例的自动曝光
构建了一个包含5000个场景的数据集,并手动给每张图片标注 短曝光参数 和 长曝光参数,前者用于采集图像的曝光参数,后者用于后面 tone map 的参数。给定一帧raw的输入图像,提取他的特征描述符并在数据库中寻找与他对应的候选样例,然后将所有候选样例手动标注的两个参数分别做一个简单的加权融合。
用于计算特征描述符的图像保证是白平衡的
是在大幅下采样的版本上计算特征描述符,用于量化场景亮度分布
四组64纬的特征,其中两组在两个不同的尺度空间上提取的,其中两组提取自图像 max(R,G,B) 和 avg(R,G,B);前者用于代表频率空间的曝光,后两组用于关注颜色削波 (color clipping ?????不懂)
带注意力的特征提取手段,通常情况下计算特征时都是给与图像中心更多的权重,当选择中人脸时也可以给与选定区域较大的权重。
选取候选实例中亮度在当前场景亮度8倍的实例,以防止昼夜颠倒的不真实情况
曝光参数分解
通过前面可以计算出 长短曝光参数。那么这一步就是要将从实例中查询计算的短曝光参数 分解为 真实的相机参数(相机曝光时间和曝光增益)然后修改相机参数再去采集图像。这一步使用一个固定的策略来 平衡噪声 和 运动模糊(如果曝光时间长就会有运动模糊)之间的关系
对于亮的场景,曝光增益设置到最低,而曝光时间提高到8ms
当场景变得暗时,曝光时间固定8ms不变,曝光增益x4
最后曝光时间和曝光增益一起成比例的提高,曝光时间上限100ms 曝光增益上限96x 为了尽可能提高采集图像的信噪比,尽可能提高曝光增益
(这个过程不是很理解 为何要这么做 以及前面的短曝光参数在这一步做何用?)
图像数量(burst size)
在较亮的场景 使用1~2张图即可,因为噪声不多,虽然多一点图也可以抑制运动模糊啥的。在低光照环境下 或者 高动态场景下,通常要将低亮度的区域亮度拉升,会有噪声,因此需要较多帧去噪,提高信噪比。
通常作者 会限制 图像数量才 2~8 张
图像流采集
自动曝光算法运行在ISP之前。每四帧图像做一次 自动曝光的参数 计算,计算一次大概10ms,没必要每次都计算因为场景不会急速变化,但是也不能太久计算一次参数,免得场景切换时显示有延迟。
另一个问题就是,高动态场景中如果包含大量过曝的像素,对估计 低曝光参数 有影响,因此作者通过 忽略 部分过曝像素来计算 匹配参数能较好地匹配样例中相似的低光照场景 (?)
帧对齐
常用的对齐方法是光流对齐,这种方法可以对齐非刚体形变,但是计算复杂度很高。出于速度、内存和性能(毕竟是移动端)的折衷考虑,作者提出了一个简单的对齐的方法,虽然这种方法无法应对非刚性形变并且误差比较大,但是后续的多帧融合算法对这个误差比较鲁棒,所以即便是使用这个简单快速的对齐方法,整体效果也可以接受。
选参考帧
参考帧选择尽可能清晰的帧。根据基于原始输入绿色通道中梯度的简单度量,选择参考帧作为突发子集中最清晰的帧。同时为了最大限度地减少快门延迟,按下快门后连拍并从前 3 帧中选择参考帧。
处理raw图像
raw数据格式实际是一整张 RGGB 排列的图像,包含了四个颜色平面。作者直接使用 2X2 的平均池化 得到 下采样的灰度图,对该灰度图像做配准。(我觉得这里不必拘泥于是不是 严格的灰度,因为最后对齐的损失函数使用像素差异来做的,即便不是标准的 RGB->gray也不太影响对齐性能)
分层配准
作者采用了一个由粗到细的配准策略。具体的是构建一个高斯金字塔的结构,先从顶层配(粗), 将上层的配准结果作为下一层的固定偏移。每层配准的表达式
image-20210628093708522
其中 u0 v0 为上一层配准的偏移结果,p 可能是 L1/L2距离,n 是计算相似度窗口的大小。u v 即为要求的 偏移;因此求u v 即为优化D的最小值。关于窗口的大小 和 采用的损失类型会在后面讨论。另外这里没有采用归一化互相关系数类似NCC中的东西对光照对比度做归一化是因为作者认为采集的几帧图像都是在相同曝光才采集的亮度一致。
边界情况怎么处理?
根据不同的尺度层,采用了不同的超参数。在粗尺度下,使用L2损失和大搜索半径来做对齐(这里的较大搜索半径如何理解?理解为偏移吧),以提高初始对齐的准确率;在底层,使用L1损失和较小的搜索半径。按照文中的说明:
最底层,使用+-1的搜索半径,L1损失,图像块为16X16
接着,对上层做二倍下采样,+-4搜索半径,L2损失
接着,对上层做四倍下采样,+-4搜索半径,L2损失
…
个人理解,最底层的L1损失精度最高,但是计算比较耗时。高层的L2损失可以做加速,优化的计算方法中这个搜索半径其实就是一个限幅的作用,并不会实际对每组偏移都计算然后选一个最优,而是最小化二次式的最优估计的方式,因此这里添加的搜索半径其实就是个限度,并不会实际影响计算速度,而这里的限度估计也是怕高层估计误差太大跑偏太远使得当前层无法对上一层的偏差纠正。由于在高层有了粗略偏移估计,所以在最低层使用+-1的搜索半径就行。
如果不采用尺度金子塔的策略,最底层就要 做一个搜索半径变化范围很大的对齐,例如可能一次就要估计出 +20 的偏移,如果使用L2加速对齐策略,这里一次L2最优估计很容易陷入局部最优,采用L1做精细搜索显然计算量很大。
快速L2对齐
image-20210628111641192
其实就是前面那个 L2 损失 可以分解为为局部和、局部平方和 以及 卷积计算两部分。前者可以通过积分图加速,后者可以在频域加速。然后假设为 D2为 待估计参数偏移 (u,v)的一个二元二次表达式,如下,我们可以通过计算几个固定偏移 (u v) 下对应的 D2值来估计固定参数A ,b c
image-20210628111927519
最后全局最优值 (u , v) 即为:
image-20210628112051053
所以这是一种近似最优的L2加速方法,不需要搜索每个可能的偏移值,只需要计算几个离散的点做一个二次多项式拟合。
多帧去噪
时域去噪
这也是该文章的核心部分,通过连拍实现对同一场景做多次观察来实现降噪。但是从上面的对齐策略可以看出,前面的对齐只考虑了刚性变化,对于非刚性运动遮挡等问题,上述的对齐方法无法估计。因此这就要求这一节的多帧融合方法可以对上述的对齐误差鲁棒。
采用了 成对的时域合并方法。
首先对每帧图像 变换到频域 T0 为参考帧的频谱图
首先一个方法,如下式,简单的将每个帧的频谱图加权平均,但是这样效果最差,因为正交变换是线性的,这样加权等同于直接在空域中对多帧取平均 ,因此如果有旋转不对齐的情况鬼影就很严重。
image-20210704160856275
接着还有 3D 卷积的方法,类似于BM3D中的做法 参考 图像处理-传统去噪算法汇总. 将时域的图像组成3D块然后先对两维变换再在时域第三维做变换,利用白噪声正交变换分布不变的思路通过新增维度的正交变换将能量进一步聚集,拉开噪声幅值和信号幅值的差距,然后采用硬阈值或者软阈值滤波滤掉噪声。但是这种方法也要依赖相似块是否对其,否则在第三维中会引入新的频带信号和噪声混合被一同滤除,相当于还是做了模糊。
最后作者的方法是 对 1 的一个改进。如下式,其实就是 (1 - A) T + A T0 A是个系数 。相当于在参考帧 和 其他帧 的频谱之间做了个线性插值,而不是直接取平均。这个插值系数由 两帧之间的频谱差异 D 计算。但是不是简单的差异,而是拿噪声的强度做了个参考,如果差异相对噪声频谱的强度很大,表明不对齐,那么就给较小的插值系数;反之给较大的权重。系数 类似 像素级别的维纳收缩的系数 ,只不过维纳收缩中 使用信号噪声的比 来确定收缩系数,这里使用 频谱功率差异和噪声的比来确定每对儿的插值系数。
image-20210704162829608
image-20210704162934904
image-20210704162947537
最后,作者说他们的方法 可以在 图像去噪质量 和 鬼影问题 做个较好的权衡
空间去噪
通过上一节对时域中的多帧频谱图像平均达到了 减小噪声方差的目的,如果是N张平均可以理解为噪声缩小了 sigma^2 / N,得到一张滤波后的二维频谱图。按照维纳滤波收缩的形式(即使用信噪比估计收缩系数) ,再在空域对频谱幅值做收缩。但是这一次根据人眼视觉特性,人眼对高频区的人造痕迹不是很敏感 ,所以根据这个特性 作者对不同频带的噪声强度乘了个系数,给高频区域更高的噪声强度,从而降低对高频区域的滤波程度(即尽可能保留高频区域的纹理)。其中 f(w) 是个分段线性的函数。通过此举,来尽量提高图像的视觉效果 而 不是 SNR
也正是这种 不同频段设置不同噪声水平的维纳滤波方法,使得最后在高对比度的区域噪声抑制效果不好
融合Bayer数据
对 bayer 图像的每个颜色平面分别对齐融合。
然后就帧融合是 一个块一个块进行的,这些块之间设置一定的重叠,为了防止出现块边缘的不连续效应,使得融合更加平滑,对块进行窗函数操作。在DFT域使用升余弦函数。
问题
这种滤波方法不能有效地抑制高对比度区域(如强边缘区域)的噪声。这是由于高对比度区域在空间DFT域的分布是非稀疏的,削弱了空间降噪的有效性。
由于算法不会拒绝一个不能完全配准的 块 ,所以有时候会出现轻微的鬼影。
有时会出现振铃效应,作者说该现象基本可以忽略不计;(若频域滤波函数具有陡峭变化,则傅里叶逆变换得到的空域滤波函数会在外围出现震荡)
合成HDR
经过配准和融合之后,拍摄的多帧Bayer raw图像合成单张raw图像,且具有更高的bit深度和SNR。实际中,输入10bit的raw数据会合成12bit的数据。得到输出raw图像后,还需要一系列的ISP后处理流程才能得到可视化RGB图像。这些步骤主要包括:
暗电流扣除
镜头阴影校正
白平衡
去马赛克
彩色去噪
颜色校正
动态范围压缩
去雾
全局色调调整
色差校正
锐化
特定色调颜色调整
dithering
其中,动态范围压缩步骤中,利用获取的短曝光图像以及合成的长曝光图像来 融合。融合方法采用了 Exposure Fusion 文章中的方法融合。但是这里作者只用了亮度这一个评判因素,计算两张图的亮度权重,加权融合(这样节省计算量)合后做gamma校正并将原来的颜色赋值上去。
问题
在极端动态范围场景,可能存在过曝光区域。在有快速运动的低光场景,为了避免运动模糊使用较短的曝光时间,可能会残留比较剧烈的噪声。在高对比度场景中,由于使用了曝光融合,可能会存在轻微的中频halos。
实验结果