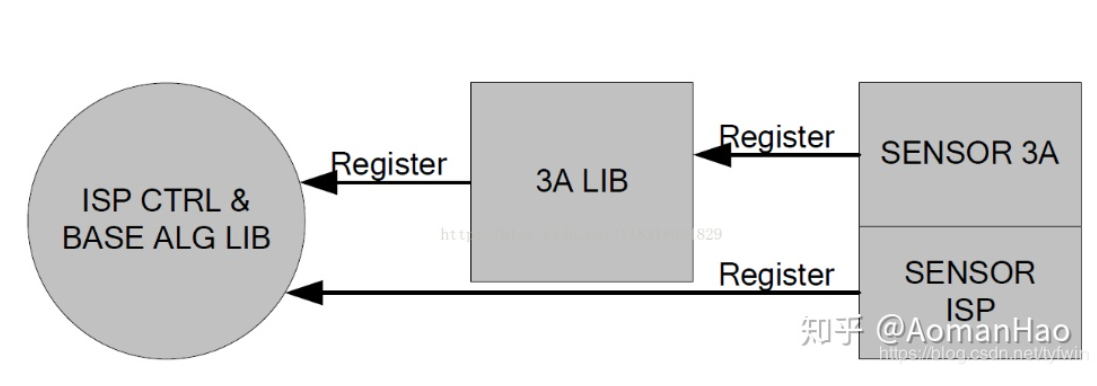
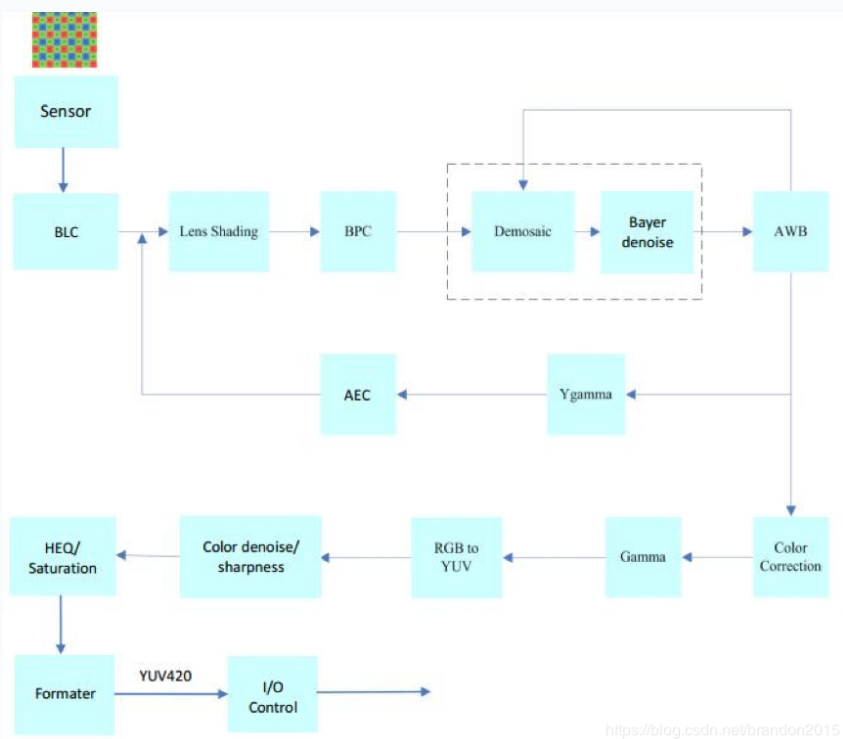
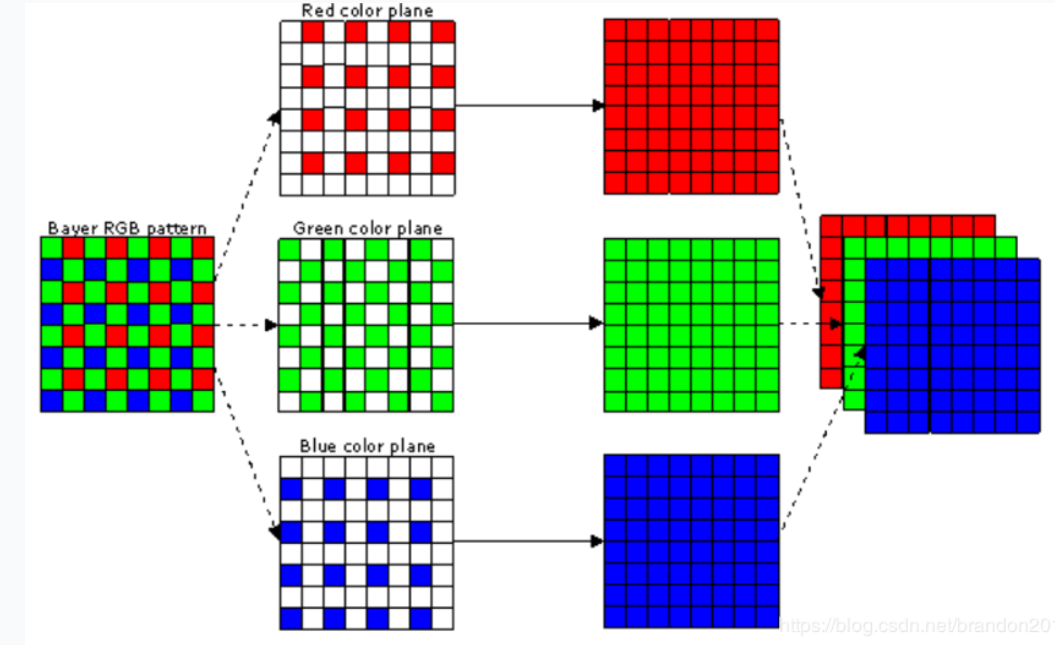
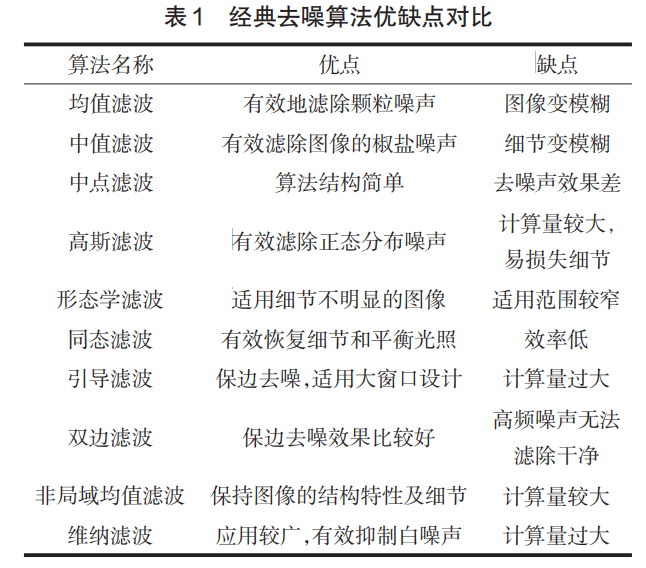
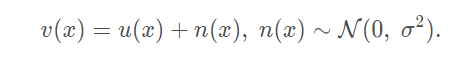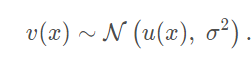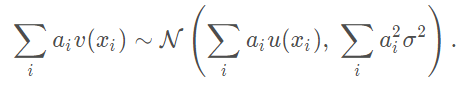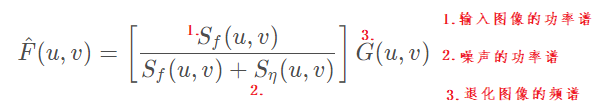传统去噪算法
图像噪声
噪声种类
图像噪声
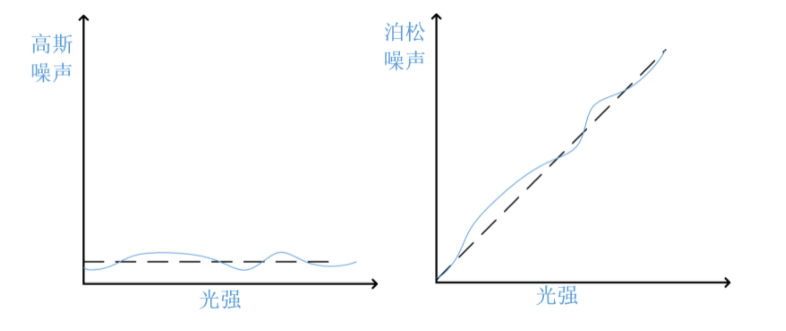
高斯白噪声:分布符合高斯分布的噪声,功率谱密度服从均匀分布,类似于白光中包含了可见光中所有频率 并且在各个频率上的功率谱密度都是一样的。高斯白噪声与光强无关,无论何时噪声的平均水平都是0。
泊松噪声(散粒噪声):符合泊松分布的噪声模型。泊松噪声随着光强增大,平均噪声也增大,但是信噪比其实随着光强增大而增大了的。
椒盐噪声:椒盐噪声主要来自于传输介质和记录设备不完善等导致。
乘性噪声:乘性噪声一般由信道不理想引起,它们与信号的关系是相乘,信号在它在,信号不在他也就不在。
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数。因为光是由离散的光子构成(光的粒子性),到达光电检测器表面的量子数目存在统计涨落,因此,图像监测具有颗粒性,这种颗粒性造成了图像对比度的变小以及对图像细节信息的遮盖,我们对这种因为光量子而造成的测量不确定性成为图像的泊松噪声
高斯白噪声
通常讨论的高斯白噪声是 加性 高斯白噪声(AWGN ),它有如下几个特点:
加性
高斯
白噪声:功率谱密度服从均匀分布,类似于白光中包含了可见光中所有频率 并且在各个频率上的功率谱密度都是一样的。
加性噪声有一个很重要的性质:
每个像素点的噪声 在 空域 和 时域都是独立无关的 ,即当前像素的噪声值,和它领域的像素的噪声值 是无关的变量。在时域是指,同一个像素位置,不同时间拍的照,噪声强度也是相互独立的。
image-20210630214759894
image-20210630215237457
其中 u 为干净的图像,n 为高斯白噪声。常用的均值滤波的方法,是多个像素点取平均,每个像素的噪声是独立无关的,加入这几个像素的 u(x) 都一样,即是相似像素。那么 多个像素值取平均 后 分布变为:
image-20210630215244594
如果 u(xi) 是常数,那么加权平均后的 u(x) 不变;对于第二项,噪声的方差明显成比例的缩小。 例如 一个噪声分布 nx(0, 1) ny(0,1) 对他俩加权平均 0.5 x nx 之后 分布变为 nx(0, 0.5^2) ny(0, 0.5^2) 两个乘系数后的分布再求和 n(0, 0.5^2 + 0.5^2) = n(0, 0.5) 所以均值后方差缩小了很多,就得到更干净的图像。
上述理论也是 目前各种 空域去噪方法 例如 均值滤波,高斯滤波, 非局部均值去噪 的理论基础。
像素取均值可以使高斯噪声方差成比例的缩小,但是上述推导中 是假设 加权的像素原始灰度值一致,最后均值滤波后才能保证 不改变原有信号,同时使得噪声的方差成比例缩小。但是 领域的均值像素他们原始的 u(x)不一定相似,所以均值滤波一定成度上也会使得原图的纹理和边缘模糊,便有了以下方法的改进来尽可能保留细节。
高斯滤波对领域像素加上了权重来避免过多的模糊原始的信息
非局部均值滤波,根据相似块的相似度来加权
双边滤波同时考虑空域和值域相似性,所以它的细节保留效果更好
多帧去噪方法则利用了噪声时域上的独立性,同时如果帧之间像素完全对齐,那么这种完全没有模糊原始细节的问题
变换域去噪
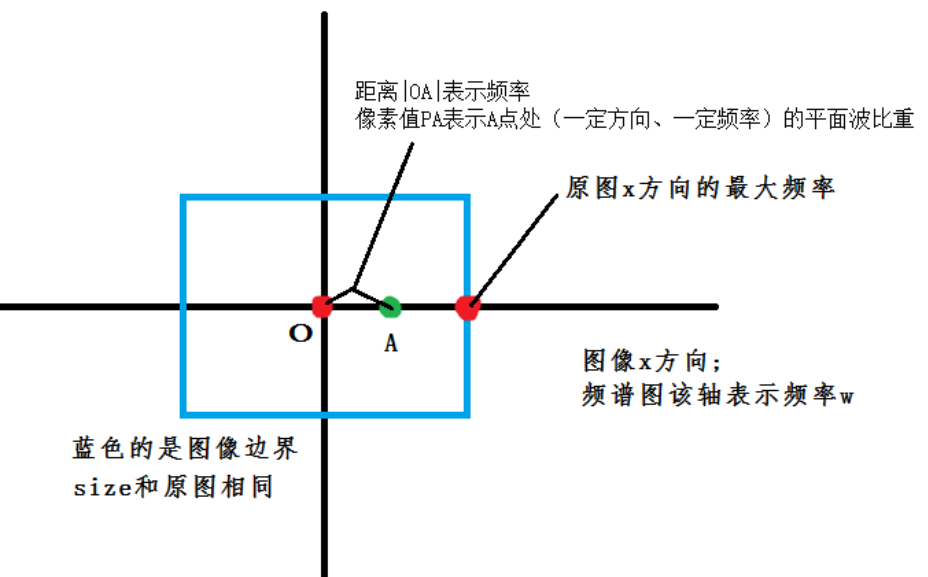
图像频谱图
将图像进行二维傅里叶变换,可以得到图像的频谱图
1 2 3 4 5 6 7 8 9 10 11 12 13 I=imread('C:\Users\10729\Desktop\1.PNG' ); I=rgb2gray(I); I=im2double(I); F=fft2(I); F=fftshift(F); F=abs (F); T=log (F+1 ); figure ;
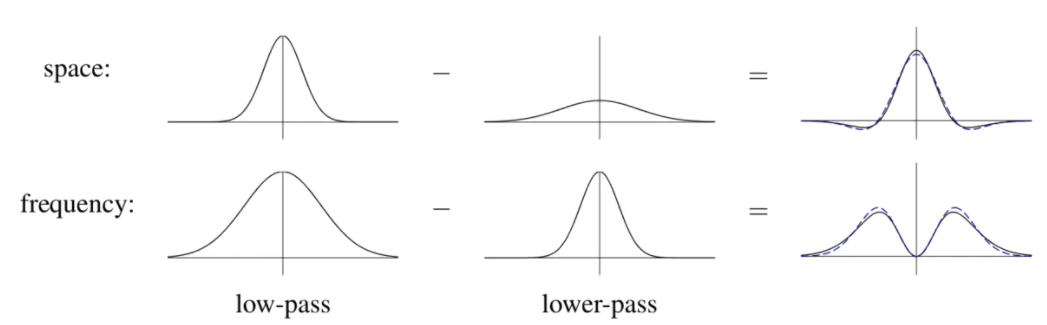
首先,图像的频谱图实际是和空域图像的梯度大小和方向息息相关。频谱图中心代表 频率为0的直流分量,两个轴一个为 x 方向的频率,一个是 y 方向的频率。但是不存在负频率。我理解的频谱图应该是 中心对称的。距离中心 O 越远代表频率越高,即空域图中梯度越大(离x轴越远代表该方向的频率越大,离y轴越远表示另一方向的频率越大,可以简单理解为 dx dy)。
频谱图的:
x, y 轴:代表两个方向的频率(可以理解为两个方向的梯度)
距离轴的距离:中心处为直流分量,距离轴越远表示频率越大
x, y 唯一确定了一个频率带
频谱图的像素值大小:代表能量的大小 例如 全 0.1 的图像的频谱图中心直流分量 > 全05的图像的频谱中心直流分量
空域图中 相同频率的像素越多,那么在频谱图中聚集起来能量也会越大。例如 将图像尺寸缩放前后,大图的直流分量幅值更大
高斯白噪声正交变换
结论 :高斯白噪声的正交变换(傅里叶变换)任然是高斯白噪声;或者说 高斯白噪声的正交变换系数同样是高斯白噪声
可以做如下试验,取一个含有高斯白噪声的图,把他看作空域图像。对他做傅里叶变换,得到一个频谱图,发现它个变换之前的分布类似。即 上述结论。
直观的理解 :对于图像空域像素中每个点,该点的像素值是个符合高斯分布的随机值,它和它领域的点是独立互不相关的,因此它领域的点也是个高斯随机值。那么他俩做差即为图像的梯度,这个差值 = 高斯分布1 - 高斯分布2,所以差值的大小依然服从高斯分布 。而根据频谱图的直观理解,频带 近似于 梯度。高斯图像的梯度幅值是高斯分布,那么可以等同理解为 高斯图的频谱图也是 高斯分布的,即再每个频带上的像素比例是个不确定的比例,它服从同样的高斯分布,只不过变换前后 像素值大小的物理意义变了。详细证明:证明
常用的频域滤波方法
低/高/带通滤波
这个就是利用 频谱图 分离频率的特性,使用一个掩码对 频谱图指定的频带进行过滤。然后反变换,使用高斯高通滤波可以 起到瑞华边缘的作用,高斯低通滤波可以起到模糊的作用
阈值滤波
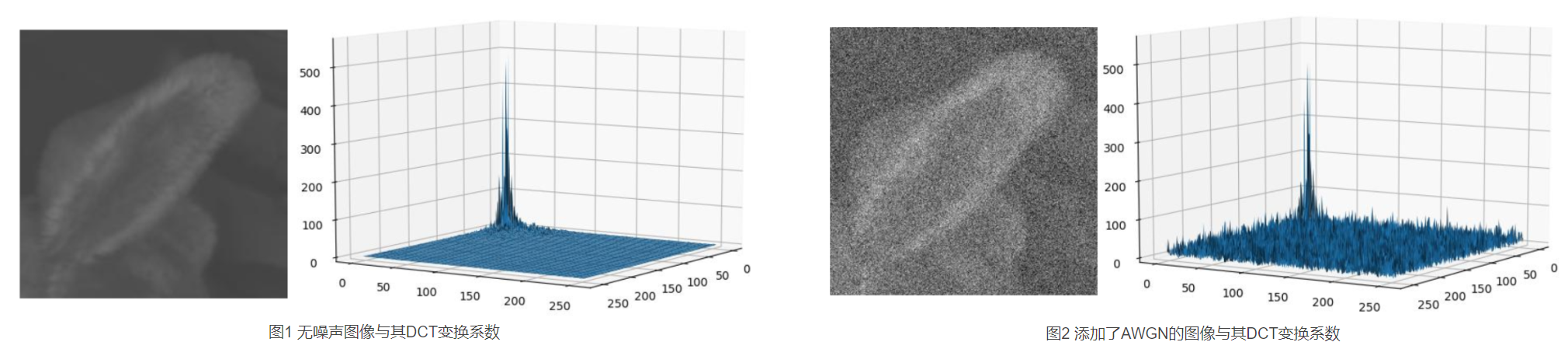
首先,常规的干净图像,它的频谱图在直流分量应该有较大的幅值。而高斯白噪声的正交变换后的频谱图依然是 同分布的高斯白噪声,例如下图:
image-20210701200050585
叠加有高斯白噪声的图像的频谱图相当于 在 相对原图 在每个频带 又叠加了一个高斯白噪声。但是这个高斯白噪声的幅值分布范围是是在 3 sigma 以内,当噪声sigma较小时,可以采用一个阈值法将频谱图 较低 幅值 的地方直接设置为0,认为这些是噪声对应的频带,但是这样无法去除隐藏在 直流分量中的噪声,所以不彻底。并且当噪声sigma较大时,也会使得 噪声和 部分图像的其他分量混合导致误杀,使图像模糊。
协同滤波
协同滤波其实是在 频域 中利用了 多帧去噪的原理。上述阈值滤波存在的问题是,当噪声幅值较大时,会和边缘细节混合在一起,导致阈值无法区分。协同滤波的关键步骤: 高斯白噪声无论变换几次,依然是同分布的,即幅值不会增大
以一个一维度的原始干净信号(干净图像的某一行为例子)
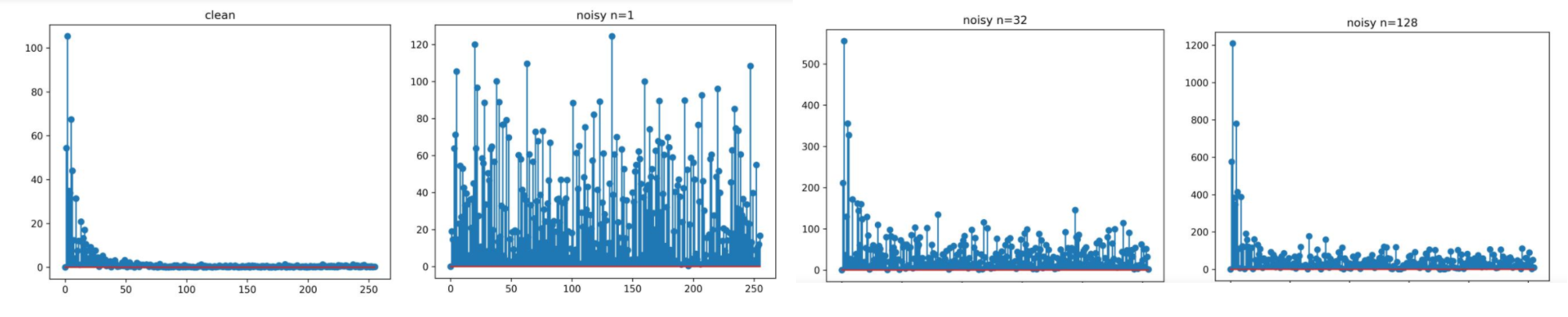
干净的原始一维信号正交变换后如左上角图所示,大部分平缓低频信号 (将直流分量置0了,免得影响观察(红线))
在干净信号上加较大方差的高斯噪声后,噪声在各个频带上的能量都有,且大小可以和干净信号的幅度相当,无法阈值滤除
取多个这种信号组成一个二维数据,现在原始维度上正交变换,再在新增的叠加维度上正交变换,然后取第一行,在新增维度上正交变换后 直流分量聚集向第一行(这里又是直流分量了,因为叠加的是相同的原始信号,他们在每个频带上的能量分布是一样的),所以在新增维度上正交变换会把每个原始信号的每个频带的能量聚集在第一行。取出此时的第一行显示。
从上述看出 新增维度得是相似的原始信号,这样他们在对应频带上能量分布才能一致,这样在新增维度变换时,可以将这个一致的能量当作直流信号聚集起来。否则会引入新的高频信息,但是这部分高频信息如果无法和噪声区分就会被滤掉 ,而噪声无论正交变换几次分布不变,能量不变。这样就拉开了噪声和信号能量之间的差距,再通过阈值即可得到较好的效果
为什么不直接像素位置取平均呢?如果仅仅是相似的图像块,直接取平均很明显会情况更糟 ,而且频域取平均和时域取平均没区别。
协同滤波中相似块的堆叠 其实和 非局部均值滤波思想类似,只不过一个是在时域对相似块的利用,一个在频域利用 ,后者计算复杂度低很多,但是对细节保留效果不好,因为该算法本身并没有把噪声的方差缩小 ,而无论我们怎样把低频分量的能量集中,总会有一些细节部分的的能量会被淹没在噪声当中,无法恢复。
image-20210701213302939
维也纳滤波
图像处理-逆滤波和维纳滤波
维纳滤波 是在频域中处理图像的一种算法,是一种非常经典的图像增强算法,不仅可以进行图像降噪,还可以消除由于运动等原因带来的图像模糊 。运动模糊可以在空域建模为卷积退化,将退化图像变换到频域,可以将 卷积 分解为点乘,然后寻求一个和干净图像的频谱均方差最小的解。将卷积信号设置为 1 即 不存在运动模糊时,就变为单纯的去噪方法,为下式:
image-20210701214422250
对于输入图像的功率普,干净图像的功率谱接近可以近似,噪声的功率谱使用固定方差去生成噪声图然后计算功率谱(所以这就得知道噪声的方差否则去噪效果不好)
从上式直观的看,其实和前面的阈值滤波有点相似,本质上也是对噪声频谱的幅值进行抑制 ,只不过这个通过优化推导出的是最优解。当某个频带 原始信号能量 远大于 噪声信号能量,那么幅值系数接近于1不抑制。当原始信号能量 远小于 噪声信号能量,系数接近于0,抑制噪声。维纳收缩
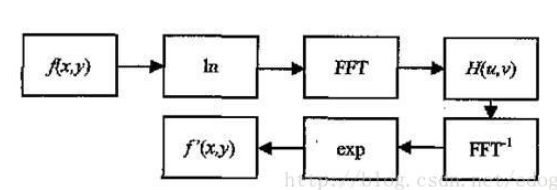
同态滤波
图像处理-同态滤波
其实这是一种 频域图像增强方法。低光照图 = 反射分量 x 纹理值 ,反射分量比较平滑对应低频分量,而纹理对应高频。首先取对数 将乘变为加 然后 变换到频域使用 高通滤波 最后 恢复。即可剔除反射分量,提亮。
空域去噪
高斯滤波
高斯滤波可以单独分为 x 方向和 y 方向分别卷积,从而降低计算的复杂度,时域卷积也可以在空域加速
双边滤波
基本原理是 空域距离和像素的值域相似度相结合, 相对高斯滤波是一种保边滤波,但是会有梯度反转的卡通效应。并且运算量大,但是有加速算法
引导滤波
基本原理有两点,首先输出假设为输入图像的局部窗口的线性表示,其次是设定一个指导图像。最终优化输出图像和指导图像的 L2 损失,是个凸优化问题。最终的效果就是 在局部高方差的区域 不平滑,在低方差的区域做均值。当指导图像为输入图像时他就是保边滤波。
非局部均值滤波
NL 考虑了和周围区域的相似度
TV变分去噪
有一系列的TV损失的变种,例如变分去噪法,非局部变分去噪,双噪声相似的非局部变分去噪 图像处理-双噪声相似性的去噪方法.
## 混合域去噪
BM3D
BM3D去噪方法讲解
image-20210701223354016
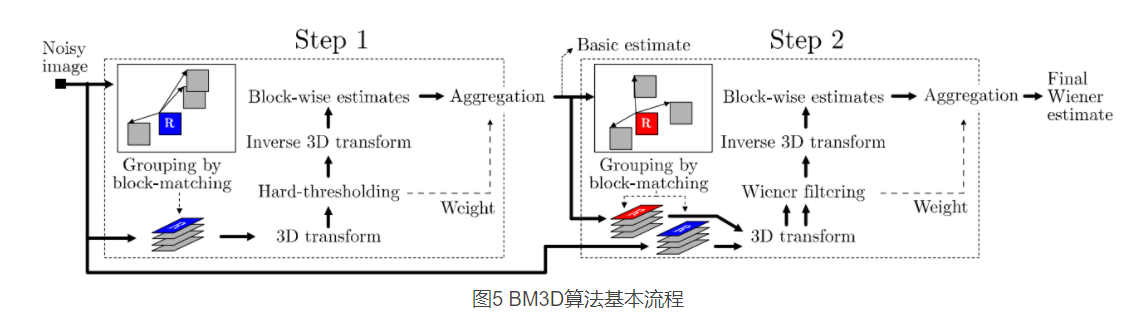
BM3D 方法其实是 协同滤波 和 维纳滤波的结合。分为两个步骤:
步骤一:
在图像领域内寻找相似块堆叠成一个 3D 块进行协同滤波,采用硬阈值的方法过滤。同时统计 非0的像素点的个数
逆变换,并将图像块还原到原来的位置。(由于一个图像块可能处在不同的 3D图像组中,因此前面统计的系数可用于加权融合 来自不同滤波组的同一个图像块)
上述步骤后得到一个初步的滤波结果
步骤二:
有了初步滤波结果,重新匹配相似块(由于初步滤波后,相似度量结果更可靠)
将相似块组成 3D 组进行变换,类似协同滤波,但是变换后不适用 硬阈值 过滤,因为硬阈值始终存在误杀的情况。由于前面已经有了一个初步硬阈值滤波后的结果,因此 结合 维纳滤波的 维纳萎缩法,已知原始干净图像的信号能量(即初步滤波后的结果)和 噪声的能量(用方差模拟),那么可以更精确地对 新的 3D组 的系数进行抑制。
抑制完毕 逆变换 ….
TV 类去噪