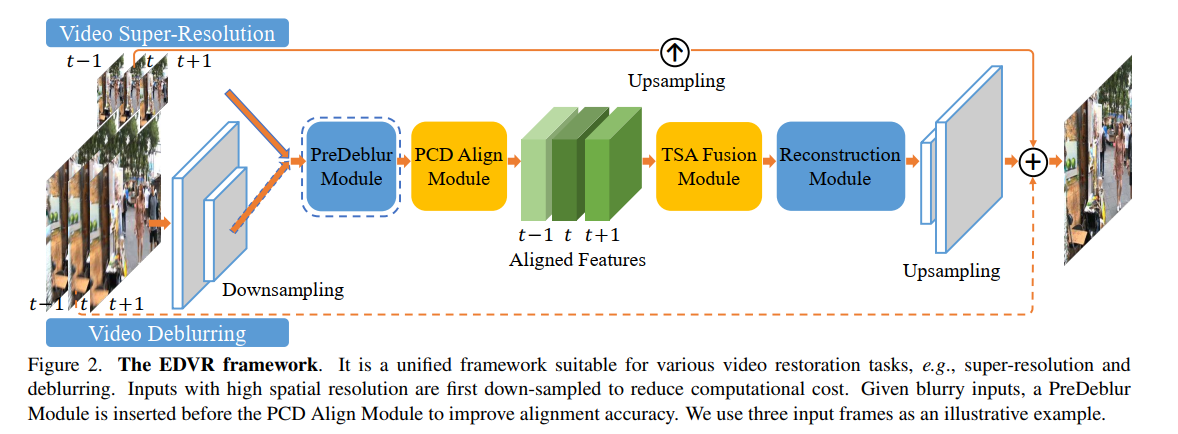
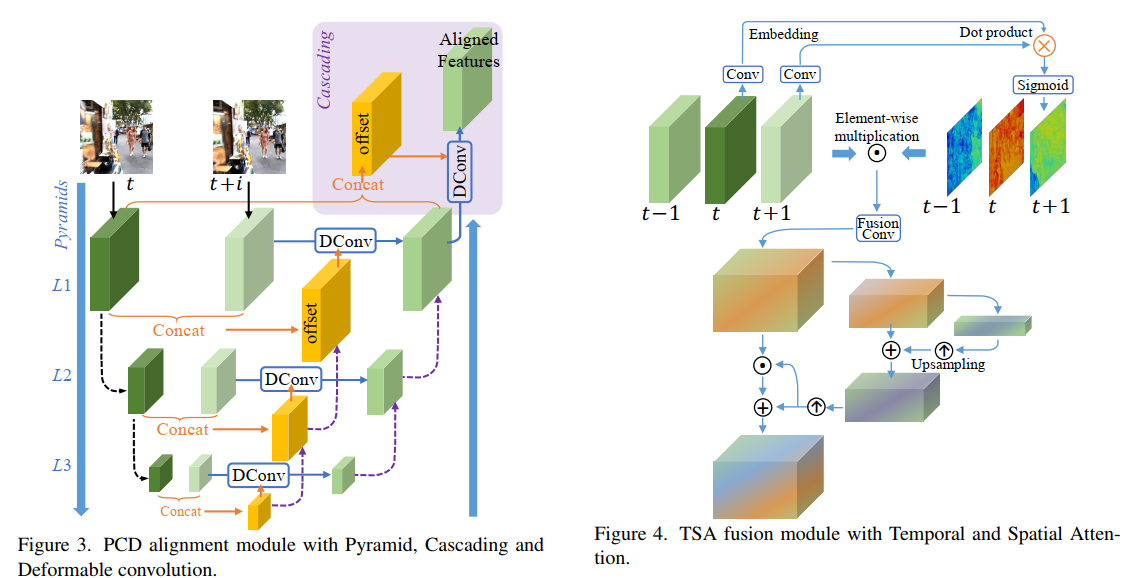
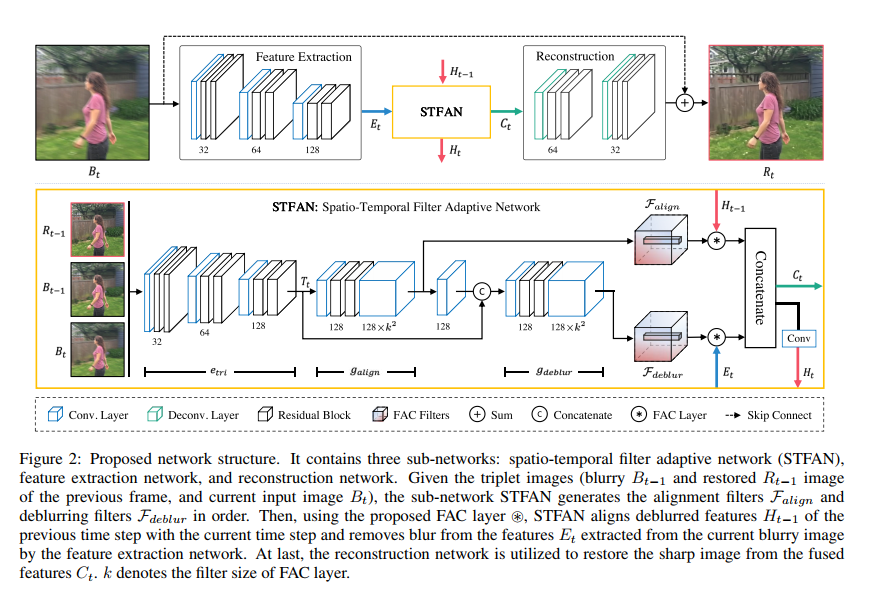
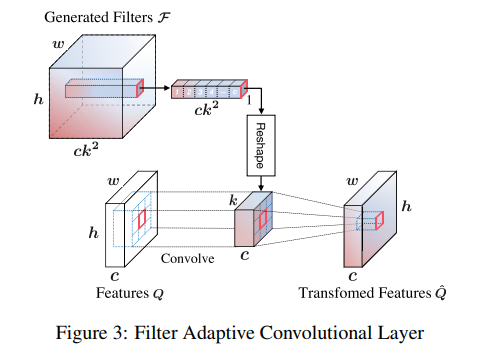
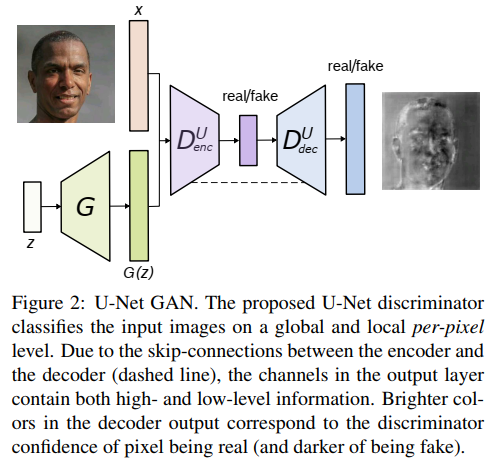
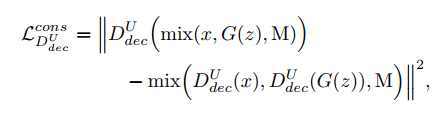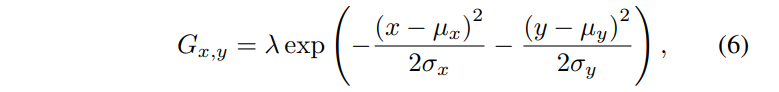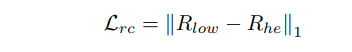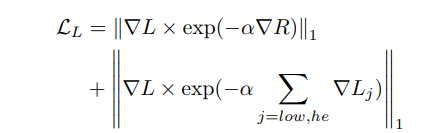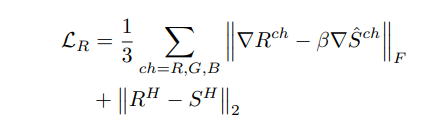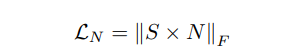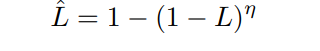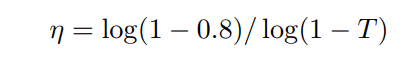A U-Net Based Discriminator for Generative Adversarial Networks
主要思想
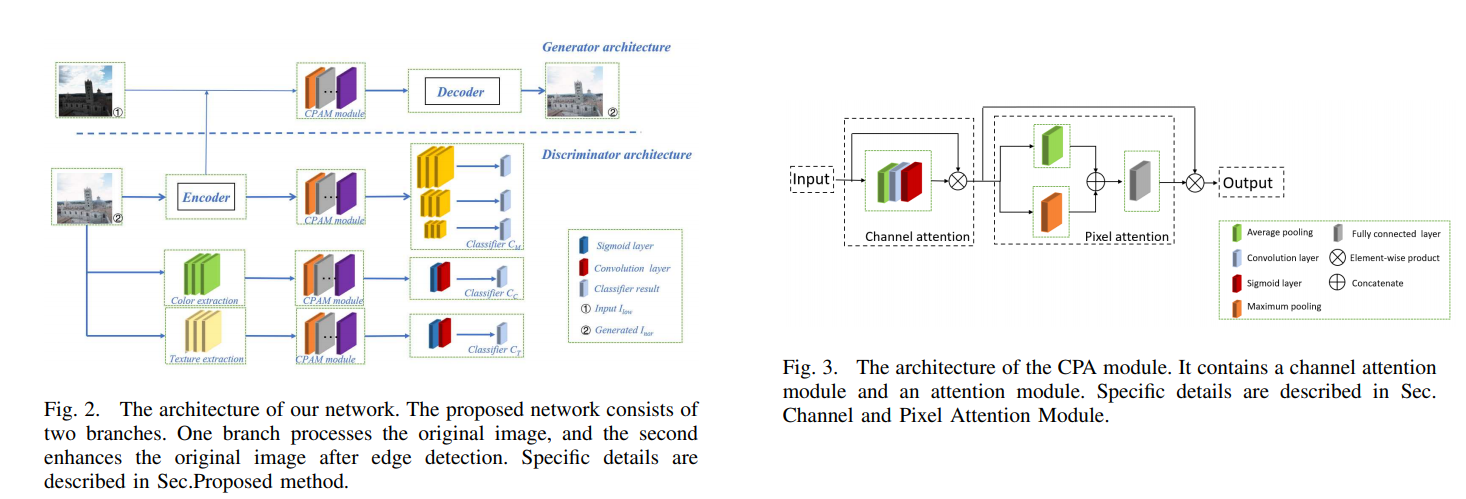
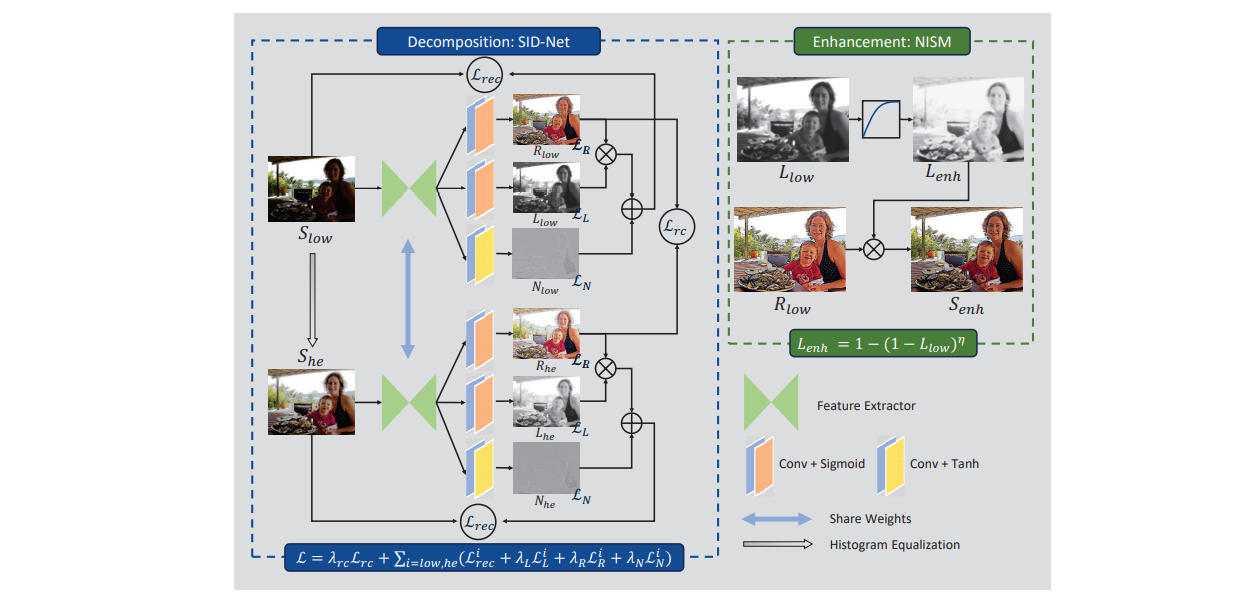
文章的工作主要是针对 GAN 的判别器的改进。使用一个U-NET作为判别器,判别器的编码部分输出对图象的全局分类结果,判别器的解码部分输出对图象像素级的判别。因此这个判别器既能判别全局也能判别局部信息。同时作者结合了 最新的正则化技术 MixCup 提出了个一致性正则化损失 。
主要内容
研究背景
GAN 目前从三个研究角度进行,即大规模训练、网络结构设计和正则化技术。尽管近年来取得了很大的进展,但如何综合具有全局语义连贯、长程结构和细节准确性的图像仍然具有挑战性。对抗器的好坏会直接影响生成器的效果。在目前最先进的GAN模型中,作为分类网络的鉴别器只学习一种表示,因此它通常要么关注全局结构,要么关注局部细节。合成样本的分布随着训练过程中生成器的不断变化而变化,容易忘记之前的任务 (在判别器训练的背景下,学习语义、结构和纹理可以被认为是不同的任务) .....
In contrast to [47], the class label c ∈ {0, 1} for the new CutMix image x˜ is set to be fake, i.e. c = 0. Globally the mixed synthetic image should be recognized as fake by the encoder Denc U ,otherwise the generator can learn to introduce the CutMix augmentation into generated samples, causing undesirable artifacts.
实验
MixCut图象的生成概率 p 在前n个epoch是从0到0.5逐步提高的。以给生成器足够的时间学习生成较真实的图片。避免判别器过早的训练稳定。一开始生成器生成的太假 判别mix难度太小。
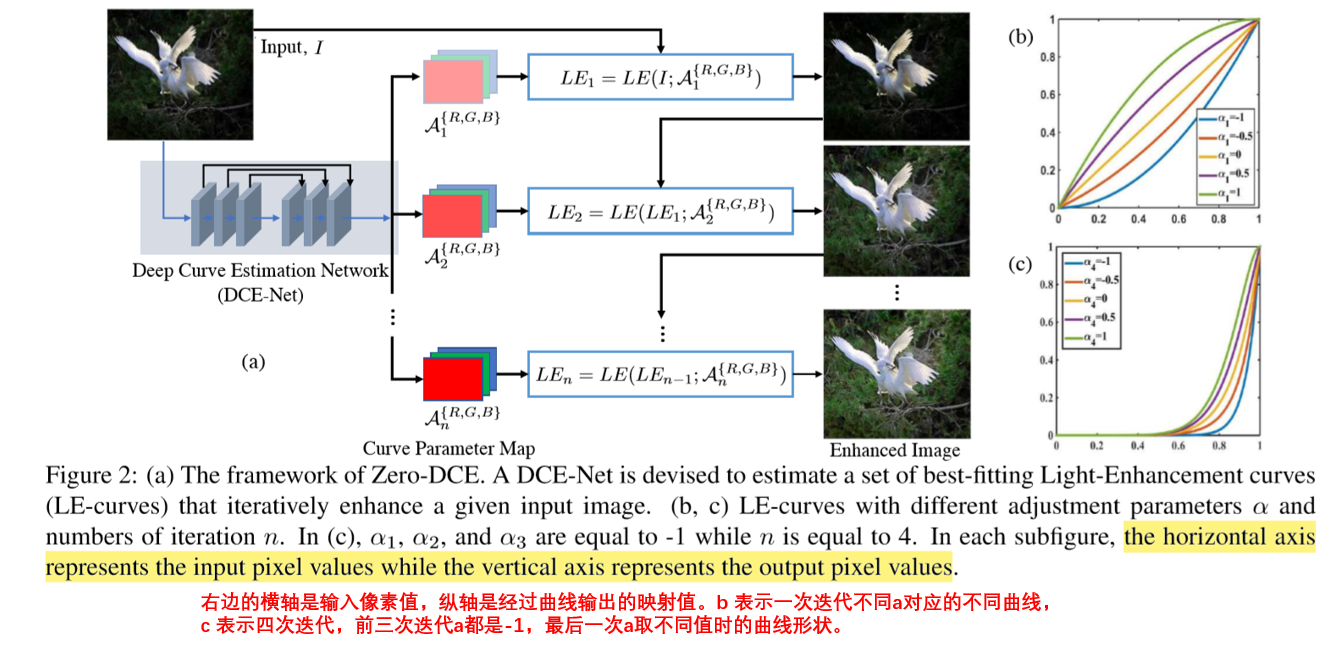
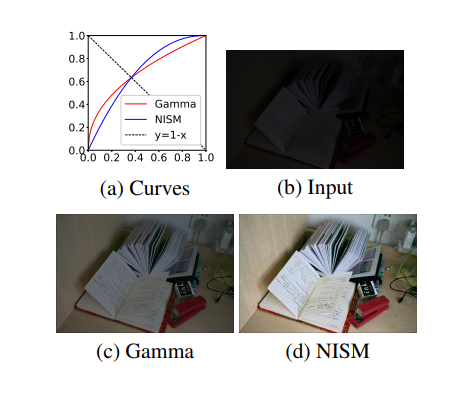
最后,每个像素位置的\(\alpha\)参数都不同,也就是不同位置的 曲线映射方式不一样,所以CNN输出的\(\alpha\)其实是和输入图像大小一样的。而由于有n次迭代,每次迭代分别对 RGB 三通道使用独立的\(\alpha\) 所以最终CNN输出的feature map的尺寸应该是n x 3 x W x H大小的。如下图: