整理、对比了常用的排序算法,插入排序,快速排序….
排序算法
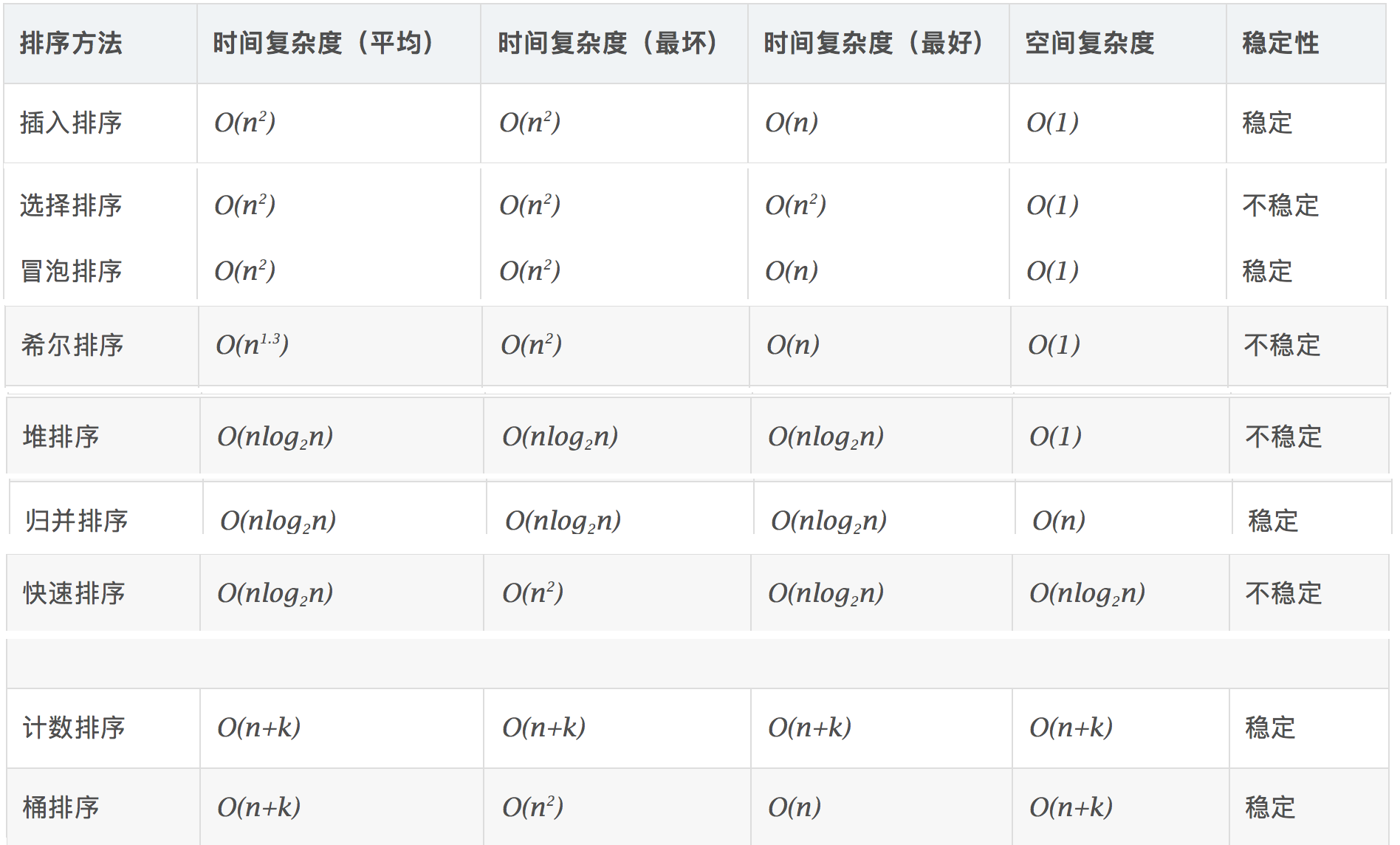
各种排序算法概述
https://www.cnblogs.com/onepixel/articles/7674659.html
- 插入排序:平均时间复杂度O(n^2) 两层循环,外循环从第二个数开始,起始认为第一个元素是有序的,每个外循环就是将当前指向的元素插入到前面已排好序的序列中。因此还需要一个内循环来完成当前外循环指向的待插入元素与前面已排好序的每个元素逐一比较寻找插入点。每次寻找插入点的过程是这样实现空间O(1)的: 待插入元素和它卡面相邻的比较,比他还大就不用比了,他就在这儿不动,如果比他小,和他交换位置,再接着往前比,直到遇到比它小的元素为止。因此整个插入过程是不断和相邻位置交换的。
- 选择排序:就是每次循环遍历序列,记录当前序列中最小的元素,将其放到序列首;再从剩余序列中寻找最小的放第二个…. 因此两个循环 。在数组实现中,空间O(n) ,不稳定 例如 5 3 5 2 第一趟选择出最小的2 和 首元素 5 交换,破坏了两个5原本的顺序,所以是不稳定排序。如果用链表就是稳定排序。
- 冒泡排序:从第一个元开始比较和他右边相邻的元素的大小,前大后小就交换,否则不动,接着第二个和第三个比,交换….直到最后一个。这样第一趟中,一定会把序列中最大的元素交换到最后。第二次冒泡就只用比较到倒数第二个元素就结束。即序列后面是拍好序的。循环执行,直到所有有序。由于每次都是相邻比较交换,所以是稳定排序。两层循环 O(n^2)
- 希尔排序:第一个时间复杂度突破O(n^2)的算法。思想是,先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序。每趟排序,根据对应的增量ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序(按照增量大小,间隔增量的元素划分为一个组)。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。这么设计算法的原因是,考虑到原始的插入排序中,当最小的元素在最后时,往前插入,要从尾比到头,循环一轮,很浪费时间。这样分组,起始组间间隔较大,可以大步长的将较小的元素调换到靠前的位置。因此 不是相邻交换元素了,是不稳定排序,时间复杂度 O(n^1.3)
- 堆排序:利用了小顶堆这个数据结构。堆是完全二叉树,因此用数组存储,首先将数组所有元素堆化(构造大顶堆),这样数组第一个元素是序列中最大的。然后将数组首元素和最后一个元素交换(即将最大的元素放到了数组最后面),因为交换了顺序,此时不满足堆的性质了,因此接着将前n-1个元素堆化,再将首元素和倒数第二个交换….循环直到堆里只剩一个元素。时间复杂度O(nlogn),涉及到首位交换元素,不稳定排序,空间复杂度O(1)
- 快速排序:快速排序的思想是,每次从序列中选择一个基准数据,然后将比他小的数放他左边,大的放右边。这样再递归的对它左边子序列和右边子序列执行上述过程的快排。分组的过程是这样的,使用双指针,默认每次选取序列第一个元素为基准元素,初始数据遍历指针和数据存储指针都指向基准后的元素,遍历其后每个元素,如果小于基准数据,就和数据存储指针指向的数据交换,在将数据存储指针自增,每时刻,数据滑动指针总在存储指针之后的。由于这个分组过程也不是相邻元素互换了,所以是不稳定排序。空间复杂度是因为递归需要额外数据保留空间 O(nlogn)
- 归并排序:和快排一样也是用了分治的思想。递归函数作用是将数组指定区间变为有序。因此函数中,先对左半部分递归归并,使得左半部分序列有序,再对右半部分递归,使得右半部分有序,最后归并,将两部分有序的序列合并,使用双指针的方法,合并时需要一个辅助数组,因此空间复杂度O(N),涉及到二分法所以时间复杂度O(NlogN) 同时 归并递归到最底层就是相邻两个元素的比较,所以是稳定排序。
- 计数排序:计数排序只能对正整数排序。首先要确定数组中最大最小元素,来确定分配多大的内存。然后遍历一次数组,每个数据放到其对应下标的备用数组中。遍历完后,再遍历备用数组的每个位置,将对应位置的元素一次输出,即可。所有都是O(n+k)
- 桶排序:首先根据一定的函数映射关系,例如均匀映射,将数组中 的元素分配到N个桶中,再对桶中元素执行插入排序,最后将桶所有元素拼接。这个和计数排序类似,只不过计数排序的分桶映射方式是 数据 和 数组下标直接对应,因此计数排序只能应用于数据分布范围小的整数,而桶排序不限于此。
- 基数排序:基数排序的思想是,对整数的每个位 逐位排序。先找出最大元素的位数,循环,先根据个位数的值对所有元素排序,拍完之后对于只有一位的元素,就完成排序;接着根据元素十位的值对剩下元素进行计数排序,对于只有两位数的元素也排序完成…..O(N*k) K为位数。每一位的排序是一个计数排序 为 N。
快排
- 快排相对 堆排序 而言 局部性更好,因为快排比较的都是相邻的元素,更方便利用缓存,而堆排序比较的两个元素之间可能距离很远,局部性不好。
- 快排相对归并排序空间复杂度更低,归并Nlog(N) 快排 log(N)
所以快排实际用的最多
快速排序的核心思想是在待排序数组中选取一个 基准数据(原则上要尽量保证 基准数据正好是中位数,这里以常用的第一个元素作为基准数据,基准数据选的不好 算法的复杂度会达到O(n^2),但是平均复杂度趋近O(N))。首先以数组第一个元素为基准a,将大于a的元素都放在a的右边,小于的放在左边。再递归的在左右区间使用这种策略直至排序完成。具体的伪代码:
1 | class Solution { |
堆排序
堆排序的要点
- 连续数组存储,对于每个节点 i 它的 左 / 右 节点的下标 2 x i + 1 / 2 x i + 2
- 建立堆的时候,每次从最底下非叶子节点开始 向上判断 节点是否大于子节点的值,若不是 和较大的节点交换值,然后再递归的调整叶子节点。因此可以看作是两个循环
- 构建好大堆之后,每次将堆顶的元素和最后一个元素交换,然后将堆顶元素下沉淀,然后将数组长度减一接着交换…
1 | class Solution { |
桶排序
桶排序的原理是,设置 m 个桶,桶是有序的,首先将 n 个待排序数分别放到对应的桶里,然后再分别对桶里的元素进行排序。假设桶内的元素使用 快排,复杂度是 O(nlogn),那么桶排序的复杂度为 O(N + M X (N / M) X log(N/M)) = O(N + Nlog(N / M)),当桶的数量接近于数组的长度时,复杂度接近O(N),因此对于数据分布均匀的数组,采用桶排序效果较好。桶排序的缺点是空间复杂度高,且实际数据并不是接近均匀的情况,因此效果一般。
典型的例题
最大间距
自己一开始做的时候,想到了用桶排序,但是把题目要求的空间复杂度看成常数的空间复杂度,感觉桶排序不满足。那如果是要求线性空间复杂度为啥不找出最大最小值,然后用Hash标记一下某个元素是否存在,然后枚举呢。当时也是没一下子想到桶排序的抽屉原理。
1 | class Solution { |
存在重复元素 III
涉及到 区间 的问题,都可以考虑使用桶排序 加速计算。首先看到这个题能想到暴力的解法。遍历数组每个元素,判断它和它前 面K个数的差的绝对值,如果小于等于t 则找到满足要求的数,返回true,否则继续。但是这样的时间复杂度为 O(kN)。如何优化呢,可以将这个题抽象为:
对某个数 x ,如何快速的在它前 k 个窗口数组中 找到 存在一个在 [x-t, x+t] 区间的数。
如果在和前K个元素比较大小的时候,前K个元素的时有序的,那么我们就能通过二分查找的方式快读确定理K最近的数。那么时间复杂度就能降低到 O(NlogK) 。这个不难实现,通过有序集合即可,有序集合的底层是红黑数,它的插入和删除时间复杂度都为 logN 维护一个滑窗。考虑 通过 有序集合的二分查找通过函数 lower_bound来获取其中第一个大于等于 x 的元素,但是我们题目的要求是找到 x - t ~x + t 的元素, 如果没找到,只能代表有序数组中的所有数都小于 x 但是不一定小于 x - t 所以还得从有序数组的最后往前遍历寻找,这样还是间接遍历了。所以应该松弛的去查找,当我们希望判断滑动窗口中是否存在某个数 y 落在区间[x−t,x+t] 中,只需要判断滑动窗口中所有大于等于 x−t 的元素中的最小元素是否小于等于 x + t 即可。
还是刚才的思路,我们用有序的数据结构降低了区间查找的 时间复杂度,涉及到区间查找的问题,我们很容易想到桶排序的抽屉原理,如果 一个桶的尺寸是 t+1 那么同一个桶里的元素一定满足上面的要求,如果不在一个桶里,那么可能在相邻的桶里,但是这个不一定,一定满足,所以需要提出相邻桶的元素单独计算二者的差值。因为这个题是滑窗问题,数组的元素数量是有限的,就算数据大小是无穷大,我们也不必创建一个巨大的数组,用 桶号做哈希表的键值即可,这样桶就是稀疏的。这个题的另一个难点是,如何将 正负都有的元素,分桶,对于负数的桶号计算要加小心。这个文章对桶id计算解释的比较好