Attention-based network for low-light image enhancement
主要贡献
- 设计了一个端到端的应用于原始图像的增强网络,结合了 通道注意力 和 空间注意力模式,结合了局部和全局信息。
- 为了减少信息损失,设计了一个 ISL层 来 取代 max pooling
- 在SID数据集上评估了算法的有效性
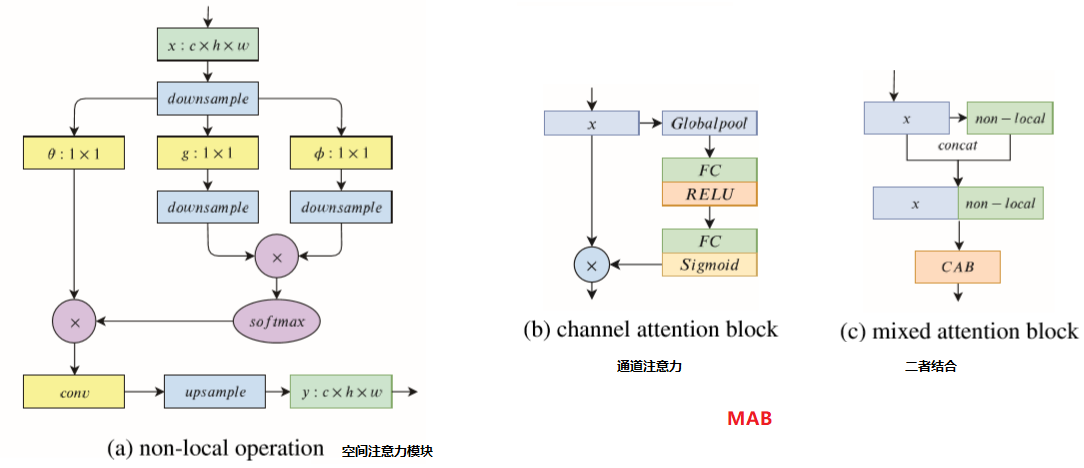
Non-local operation
原始文献:Non-Local neural networks
传统的卷积神经网络 其实只关注 局部图像的相关信息,而如果要获得全局信息,要通过很多层的卷积堆叠来扩大感受野,进而使网络形成全局信息的关注。全连接就是non-local的,而且是global的。但是全连接带来了大量的参数,给优化带来困难。基于此,作者根据 传统计算机视觉方法中的 非局部均值去噪滤波 的思想,设计了应用于CNN的 non-local操作。
- non-local operations通过计算任意两个位置之间的交互直接捕捉远程依赖,而不用局限于相邻点,其相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息。
- non-local可以作为一个组件,和其它网络结构结合,用于其他视觉任务中
非局部均值去噪滤波
传统的均值滤波的方法是 取目标像素位置的 领域区域的所有像素均值作为该位置滤波后的结果。而非局部的特点就是根据根据该局部区域和全局区域的相似度 作为加权系数来 加权平局。具体的过程如下图
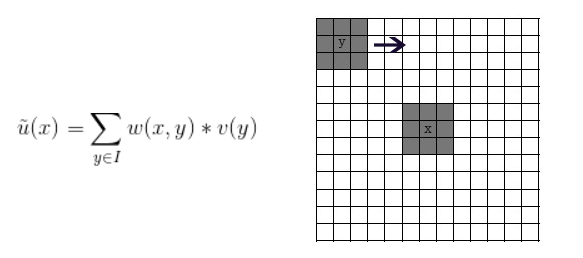
w(x,y)一般定义为一个与欧式距离(2范数)相关的函数,设x,y的邻域宏块的欧式距离为d。对于待求位置x处的输出滤波,取x领域的小block 在周围大区域上滑动计算相似度,例如y位置处的相似度 d=||block(x)-block(y)||/block_size;则y加权到x点的加权因子为 w(x,y)=exp(-(dxd / (hxh))) 这个式子将原本的距离d转化为了 0-1之间的一个加权因子w(x,y)。h为衰减因子,h越小,加权因子越小,则加权点对当前点的影响越小,一般边缘保持得好但是噪声会严重,反之则边缘保持差图像更加光滑。计算欧式距离时,有时会考虑周围点对中心点的影响,会利用核函数对欧式距离加权。加权矩阵W要归一化。参考链接:https://blog.csdn.net/qianhen123/article/details/81043217
Non-local 表达式
\[\mathrm{y}_{i}=\frac{1}{\mathcal{C}(\mathrm{x})} \sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right) g\left(\mathrm{x}_{j}\right)\]
上面的公式中,输入是x,输出是y,i和j分别代表输入的某个空间位置,x_i是一个向量,维数跟x的channel数一样,f是一个计算任意两点相似关系的函数,g是一个映射函数,将一个点映射成一个向量,可以看成是计算一个点的特征。也就是说,为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像attention:输出的某个点在原图上的attention,而mask则是相似性给出。参看下图
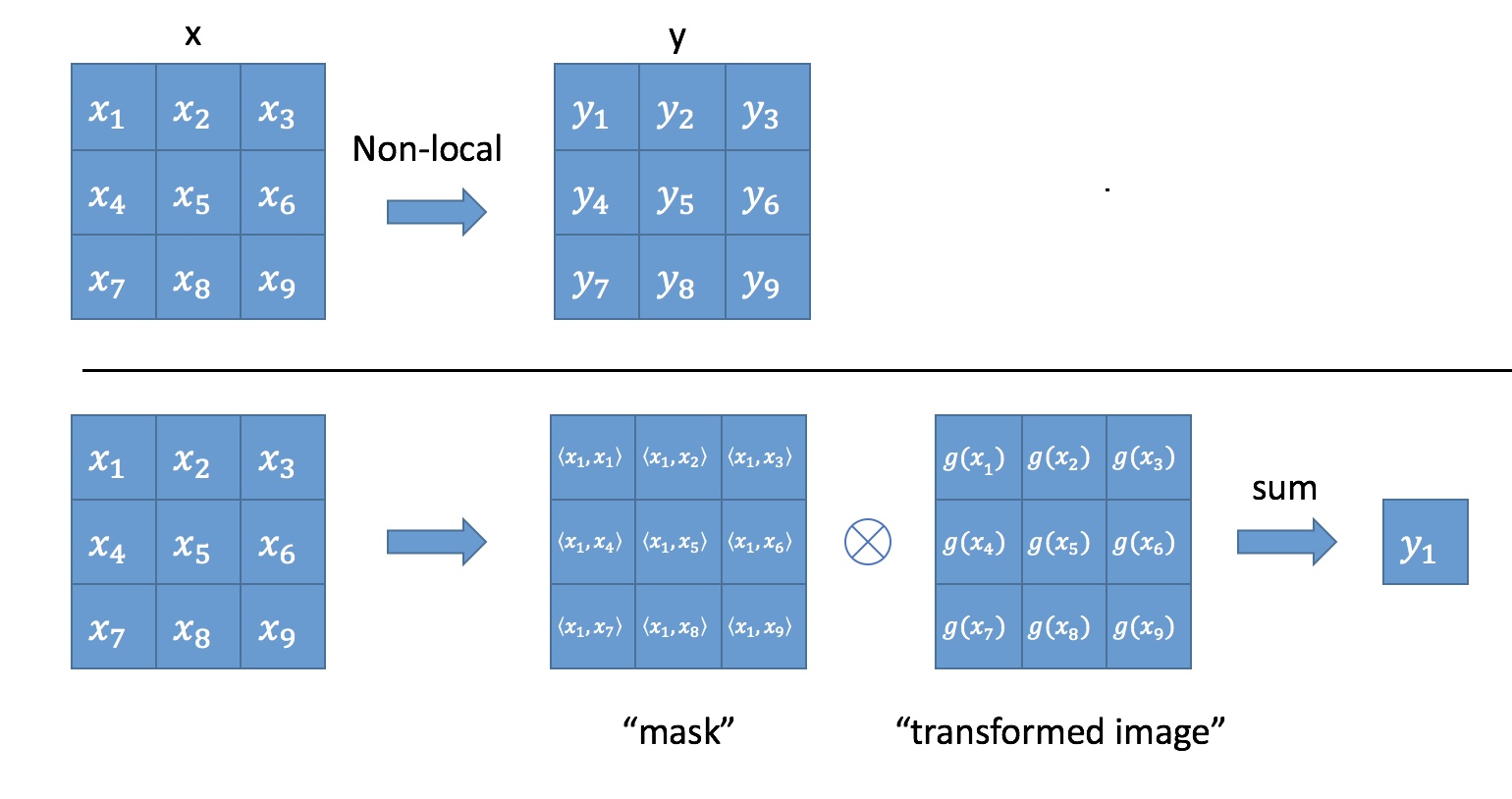
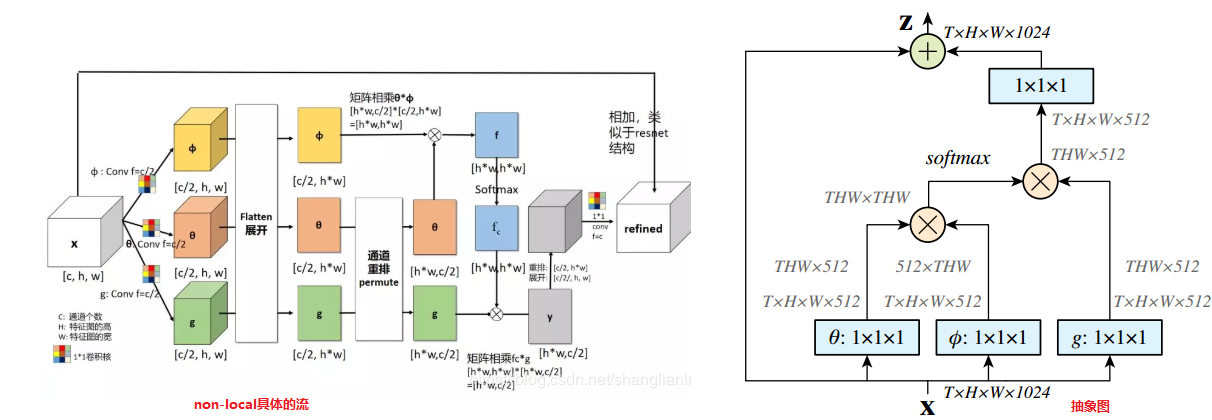
为了简化问题,作者简单地设置g函数为一个1*1的卷积。相似性度量函数f的选择有多种。具体参考链接:
https://zhuanlan.zhihu.com/p/33345791 https://blog.csdn.net/shanglianlm/article/details/104371212
1 | #### pytorch non-local实现 |
主要方法
网络结构
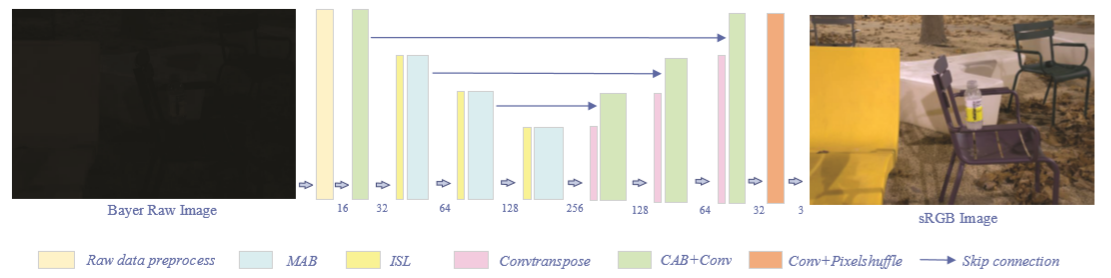
Inverted Shuffle Layer
作者说 设计这个的目的是因为常规的max pooling 虽然可以将低计算量但是会损失较多的信息,因此作者将 shuffle的思想应用到这个设计中。文章没有具体描绘结构 只是文字表述了一下,没懂到底怎样的结构
Inspired by pixel shuffle in [18], we proposed a new pooling operation, named ISL, which includes inverted shuffle and convolution operation. After an inverted shuffle operation, the size of the feature map reduces to half of the original and the number of channels quadruples. Convolution layer with 1×1 kernels is performed after the inverted shuffle, which plays a role in selecting useful information while compressing the number of channels. In general, ISL not only has the effect of reducing the computation as a pooling layer but also makes the network more flexible to select features.
损失函数
就是采用常用的 SSIM 和 L2损失结合。
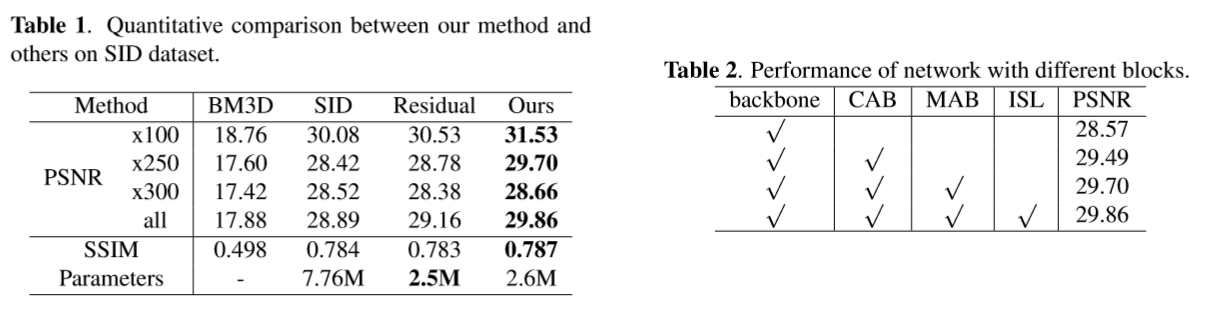
实验结果
训练
这个文章可以算 learn to see in the dark 文章的补充,和它一样使用原始图像数据,只不过将注意机制等融入网络设计。训练集和测试集都是用的 SID。
结果