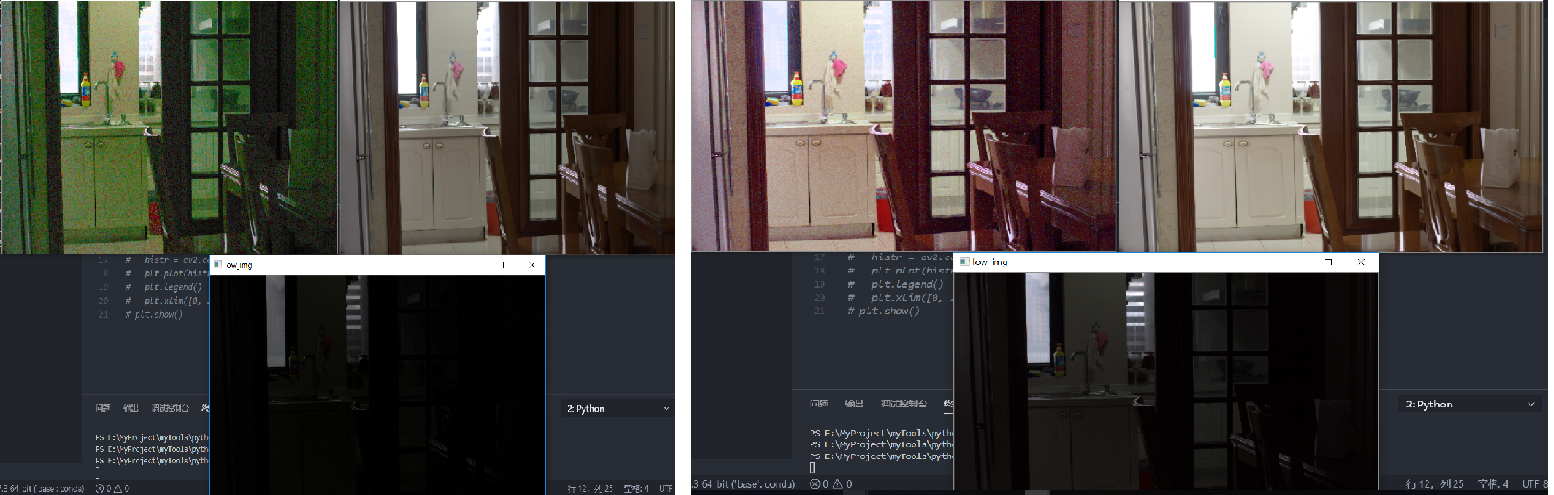
- 将成对的低-正常光照图分解为 HSV 格式,将低光照图的V替换为高光照的V通道,替换整体和正常光照图相似,但是会有一定的色差和畸变,光照越低的原图,噪声退化越严重
相机成像模型 Retinex 中为I * R 根据相机成像模型,这个应该是非线性的
局部光照一致性 距离高斯分布的局部 变分 离边缘位置越远,得到边缘的梯度损失权重越大 正处于边缘位置的最小
LIME 对于 黑色区域和暗区域也不能很好的区分 因此对黑色区域也存在过曝 LIME中 可以看出r矫正之后 光照值整体变大,相应的过曝区域变少。KinD中对 光照估计依然很低 但是反射率图 却没那么过曝 呈现黑色 主要是Kind训练时加入了纯黑的图片 低光照图是黑色 对应的强光照图也是黑色

- 对黑色区域和暗区域区别? 估计出光照图后 根据对黑色区域的预测 加以抑制对应的光照图 ?
- attention guid 学习提取暗区域的 方法是 提取高低光照图中的V的差值 max(R/G/B) 即高光照中V较大的区域而 弱光照图中V较小的区域即为暗区域 同理 黑色区域也是如此
- 其实 KindD的图像分解效果 总是 <= LIME 尤其是在对于纯黑色区域

LIME 传统光照分解
优点 :
- 图像分解效果较好 图像增强的最终结果不会太糟,对一般的图像都有普适性
缺点:
- 使用DMB3去噪效果远不如深度学习方法的效果
- 会有一些颜色失真的情况 也没办法应对
- 光照调节不够灵活 只能通过r矫正来 改变光照程度 并且也会有一定的过曝
KinD Net 基于深度学习的方法
优点:
- 图像分解网络不需要大量的高质量图片训练 只需曝光度不同的图片就可以完成整个网络的训练
- 光照调节灵活
- 含有针对特定数据集的去噪重建网络 这一点效果相对LIME直接使用DMB3效果要好很多
缺点:
- 在其他未fine turn数据上的光照分解网络性能 <= LIME 根据约束优化分解网络 在不使用大量优质参考图像训练的条件下 不如直接采用传统方法估计光照 这样估计的结果肯定不会太差 例如仅在LOLDataset上训练的分解网络在其他数据上效果较差
- 图像分解由于没有直接满足 I = L*R LIME中若 I = 0 I/L= R必定等于0 而 kind中 I != LR 只是近似 因此 当 I = 0 R 依然会趋于过曝 当然二者都有不同程度的过曝 因此LIME对黑色的区域分解结果比LIME还差
Fully Convolutional Color Constancy with Confidence-weighted Pooling
综合二者
分解网络
- 采用传统方法估计光照图 即相对全变分
- 使用深度学习的方法 来对上一步的光照图优化 如何优化?
- 使用 U-Net 拟合高低光照图片之间的距离 不收敛? ???
- 使用深度学习的方法来调整光照强度 1. 手动设置 调节增益参数 2. 数据上训练得到最优的固定的光照调整网络
重建网络
- 去噪 需要无噪声的图像 和有噪声的低光照图像 LOLDataset
- 颜色矫正 可以使用无噪声合成数据训练 / 对比度调整
只估计光照图
网络输出没加sigmoid 导致一开始损失很大 百千级别
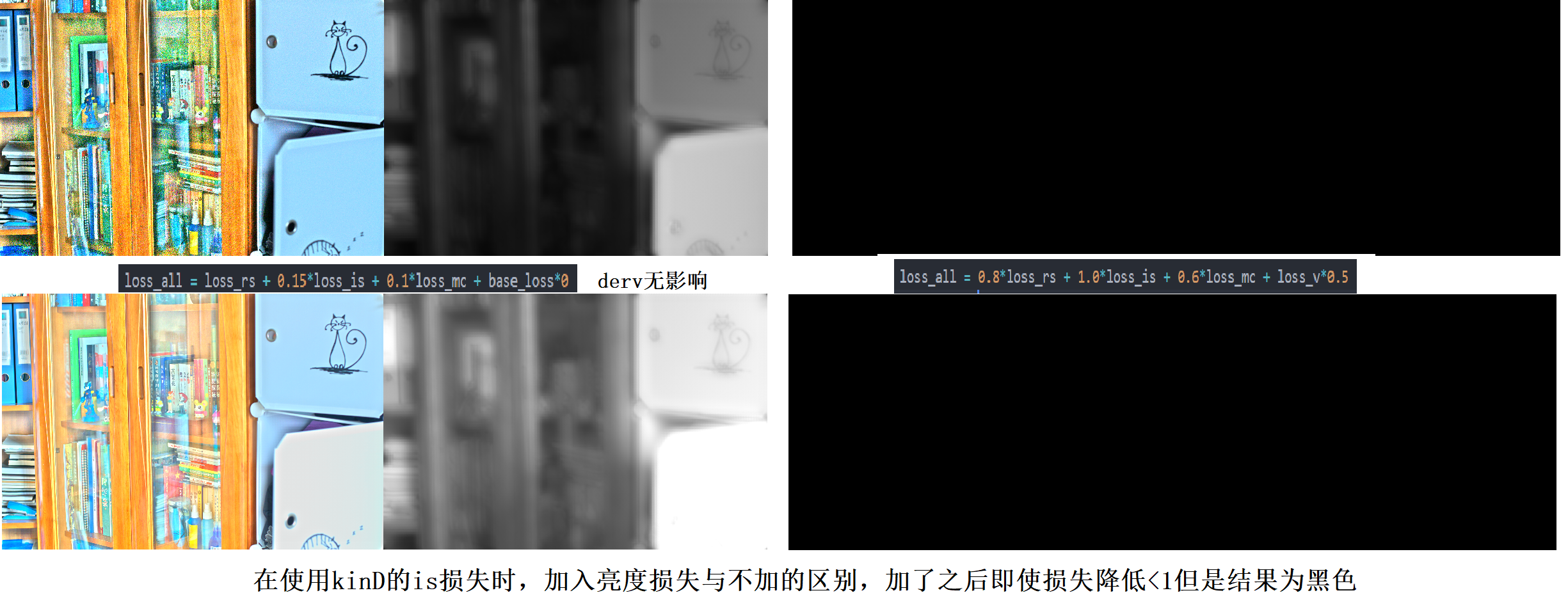
使用kinD的梯度损失,外加初始亮度损失会使结果优化不出来(此时Loss<1),同时最后一行一列补0/不补0没区别
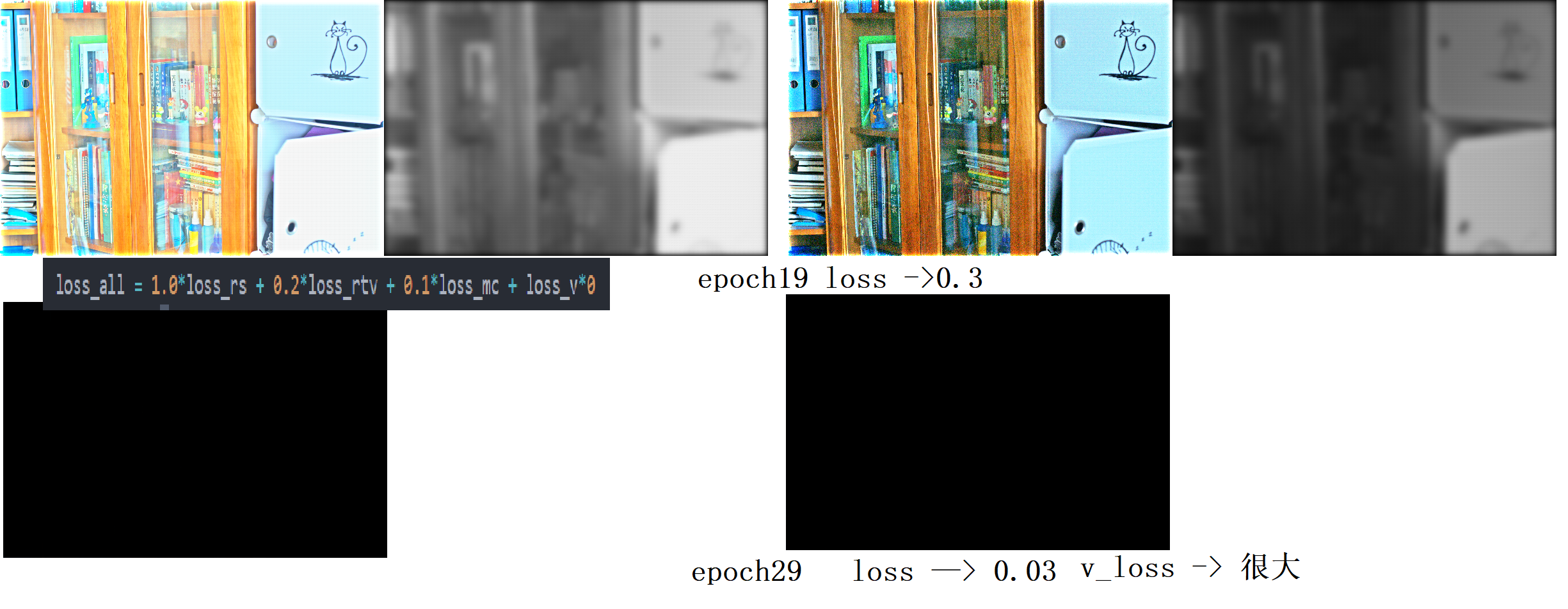
使用rtv损失,并且不加亮度约束损失,中间整体损失在0.5附近时,效果较真实,但是当损失进一步收敛,epoch20时此时极端化,可见此时亮度损失已经偏离正常值。而且亮度图中明显可见小斑点,我觉得可能是rtv权重不是连续的导致的,四角会出现光晕
加上sigmoid函数收敛的很慢 主要是 在卷积输出为很大的时候 经过sigmoid的输出趋近1 此时的梯度实际很小
实际加sigmoid的输出效果和不加的差不多

加上sigmoid之后 loss rs 的比重需要减小 否则会使得高低光照图都接近很暗 不能增强
细节调整
考虑prelu BN层对网络的影响
无监督图像增强方法
一些想法
- 因为传统图像增强方法例如直方图均衡化 他们可以作为先验知道CNN约束
- CNN中 应用 Retinex 模型的优点在于基于这种先验 可以使用更小的网络 来完成任务 而直接端到端的增强方式 需要更大的网络去拟合,也就是先验的存在降低了对网络拟合能力的需求
- 但是Retinex针对过曝的图像不友好,因为I./R的原因。而有的文章使用 曲线的方式 来增强 网络输出曲线的参数,不同像素位置的曲线不同,那么他的调整效果不同,具体的 可以增强也可以压缩像素值,而这一点是Retinex做不到的。但是感觉这种学习曲线参数和使用CNN直接端到端的映射区别不大呀。可是依然使用小网络实现了不错的效果。
- 借鉴图像先验来设计损失函数 例如 Gray-World color constancy
可以考虑的出发点
- 可不可以设计 “多专家” 的网络学习过程,即多种传统方法的增强结果做损失函数约束 + 基于图像理论设计的损失函数 来共同优化网络的学习,增加的第二项目的是 根据传统增强方法中存在的 缺陷而设计的损失函数。这样出来的结果会不会优于传统方法。
- 第一项的损失是为了约束网络的学习方向,可以考虑计算训练过程中的 结果来 动态 调整各项损失权重
- 通过什么方法 改善 Retinex 结构 的缺点?
- GAN类方法的优点
- 使用对偶估计的方法,来加强对过曝光的适应性,将传统方法使用CNN实现
- 文中 对反转的输入图像做光照估计 可以很好的抑制过曝光区域,将 三张图融合 来达到更好的效果
- 但是这么做 算法的实时性不行,一方面本来传统的光照估计方法速度不是很快,如果做两遍更浪费时间,另一方面,它融合需要计算各个图像的质量然后计算融合权重,这也是很耗费时间的步骤。
- 使用CNN来改造有如下好处:
- 尽量用一个网络来同时对输入图像和反转图像进行光照估计,减少计算量。
- 使用CNN来学习三张图的融合权重,自适应的目的 会不会效果更好。
- 可以根据已有数据来离线学习,效果会更好?
- 光照估计可以考虑全局 和 局部特征提取,KinD 的照明估计 由于学习的是局部小patch信息 而传统CNN的方法是全局优化 看起来更自然。