Learning to Restore Low-Light Images via Decomposition-and-Enhancement CVPR2020
思考
文章主要思想是 频率分解,是个新思路 但是没有在无参考图像上的对比实验,且对比的方法比较旧。文章也使用了VGG损失且确实会有效果。这种分解的思路可以借鉴,对参考图像做处理来指导网络学习期望的效果。
主要思想
作者发现 低光照图像的噪声在不同频率的层会表现出不同的对比度,在低频层中比在高频层中更容易检测到噪声。基于此思想,提出了一个基于频率分解-增强的两阶段低光照图像增强模型。也是从粗糙到精细coarse to fine的思路。同时 还提出一个新的包含真实噪声的数据集。如下图:

主要内容
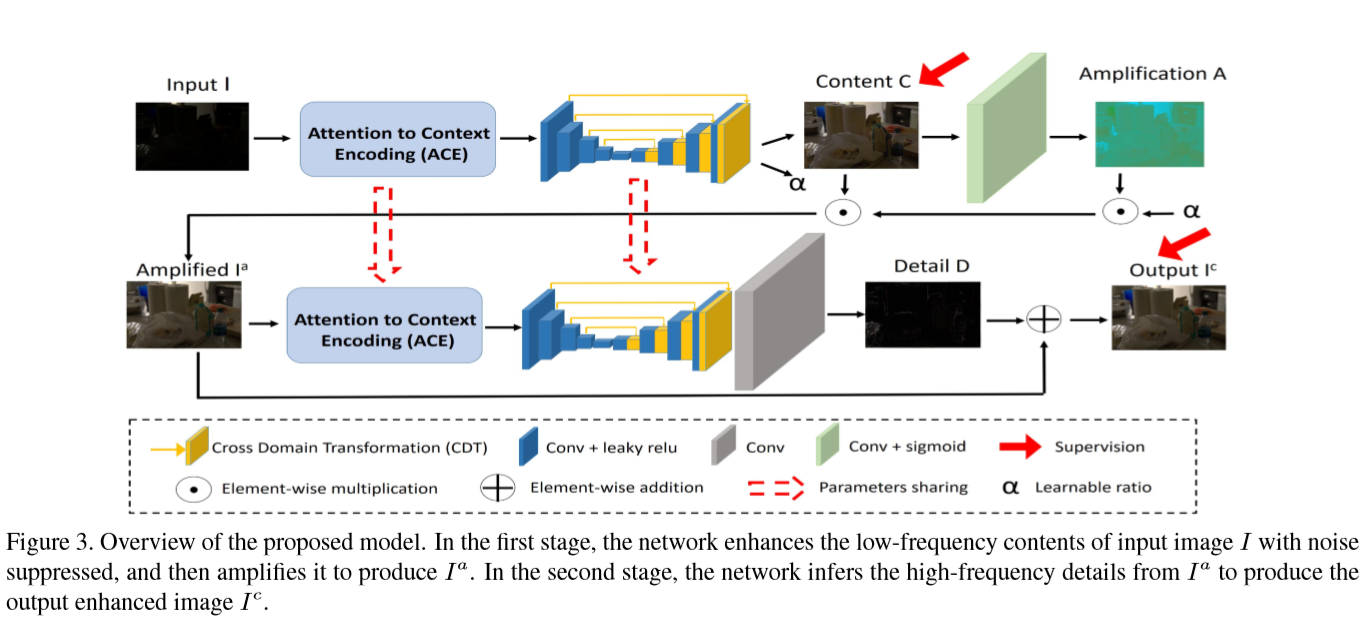
整体结构
首先,与直接增强整个图像相比,增强 含有噪声的低光图像的低频层更容易。这是因为低频层的噪声更容易检测和抑制。通过分析图像低频层的全局属性,可以正确地估计图像的光照/颜色;并且图像的边缘或者角点只占图像的很低维度(?)因此,给定基础的低频信息,可以推断出相应的高频信息。
第一阶段,输入图像,学习一个可以获得图像低频信息的网络 获取 增强后的低频图像 content map C(.),过滤掉了高频信息。然后使用放大函数 A(.) 用作颜色恢复和进一步增强。具体的:
\[I^{a}=\alpha A(C(I)) \cdot C(I)\]
\(I^{a}\)是放大后的低频图像,这里并非retinex的那种illumination map的增强,而是类似于一种attention \(\alpha\)也是和C用一个网络生成的。
第二阶段,就是根据第一阶段的\(I^{a}\)来恢复高频细节。 第一阶段C的 监督 是 参考图像经过 指导滤波后的图像(详情见损失部分)第二阶段的 监督就是正常参考图。这一部分用了一个残差结构。
\[I^{c}=I^{a}+D\left(I^{a}\right)\]
ACE模块
又总的结构图可以看出 在第一第二阶段输入的时候都经过了一个ACE模块,这个模块就是起到筛选 低频/高频 成分的功能。后面接的对应网络完成 低频/高频 图像 中的噪声去除和细节恢复。ACE结构如下:

ACE 对输入图像做了两个并列的 不同 空洞率的卷积 ,然后做了 差 生成了Ca \(C_{a}=\operatorname{sigmoid}\left(f_{d 1}\left(x_{i n}\right)-f_{d 2}\left(x_{i n}\right)\right)\) Ca 表明 像素间的相对差异,差异大的就是高频区域 反之低频。将Ca作为一个全图的权重 和 输入特征x_in点乘,来过滤高低频信息(1-Ca) 再后面的部分就是 nonlocal 模块了,作者这里进行了降采样 提高计算速度。这里在第一个图中的两个ACE是共享权重的。
CDT模块
同ACE DCT首先接入的也是 1-Ca 作为引导滤出高频区域。然后使用self attention生产vector进行channel 的缩放,就是通道注意力模块。CDT模块是为了减小输入特征和增强特征的差距 并 扩大感受野。
损失函数
损失包含了以下三项。其中 C是第一个阶段的content图,GT的指导滤波输出的低频图,最终的增强图和GT图。fi是vgg网络输出的损失。
\[L_{a c c}=\lambda_{1}\left\|C-I_{f}^{g t}\right\|_{2}+\lambda_{2}\left\|I^{c}-I^{g t}\right\|_{2}\]
\(L_{v g g}=\lambda_{3}\left\|\Phi\left(I^{c}\right)-\Phi\left(I^{g t}\right)\right\|_{1}\)
实验
实现细节
第一阶段中的 \(\alpha\) 初始设置为 1 。训练图像随机裁剪到 512X384。分辨率为1024x768的输入图像处理耗时0.33s 在1080显卡上。
对比实验
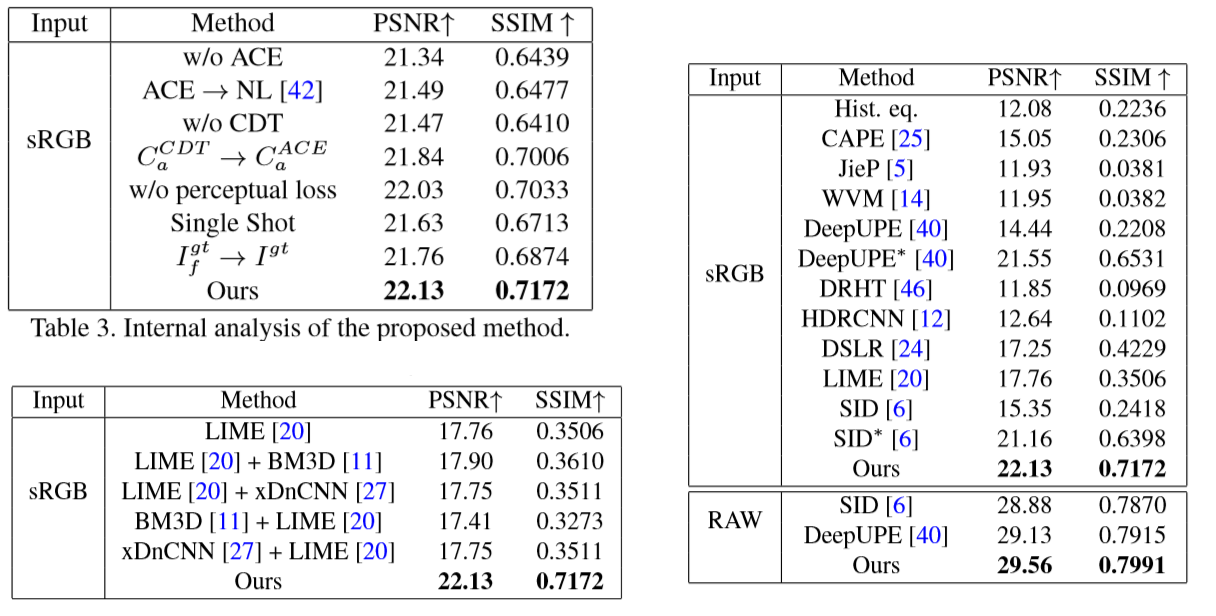
一个是 对 网络中的各个模块 ACE DCT等做了对比实验,另一个是 在自己训练用的RGB数据集上和其他发给发做了对比,再就是对 加入去噪流程的其他方法做了对比。