HDR-Net
相关论文
Deep Bilateral Learning for Real-Time Image Enhancement (HDR-Net)
Deep Bilateral Retinex for Low-Light Image Enhancement
主要思想
借鉴了 双边网格(在快速双边滤波算法中被提出用于加速双边滤波)的思想 和 局部颜色仿射不变性的 特点,将图像缩放至低分辨率 输入网络,学习局部和全局特征,融合之后转换到双边网格中,得到双边网格下的局部仿射变换参数。并行的,对输入图像做仿射变换得到引导图,并将其用来引导前面的双边网格做空间和颜色深度上的插值,恢复到和原来图像一样大小的变换参数。最后根据这个参数对输入图像做仿射变换,得到输出图像。
特点
- 大部分计算过程是在低分辨率的网格下进行的 - CNN中的局部和全局特征提取都是在低分辨率下执行。
- 学习的是输入输出的变换矩阵,而不是直接学习输出
- 虽然主要网络实在低分辨率下进行的 但是损失函数是在原来的分辨率上建立的,从而使得低分辨下的操作去优化原分辨下的图像。
主要内容
这篇文章主要是在先前的基础上进一步改进的,包括联合双边上采样(JBU),这里是通过将双边滤波器作用在高分辨的引导图去产生局部平滑但是也保留边缘的上采样;双边引导上采样(BGU Bilateral Guided Upsampling )则是引入了在双边网格里进行局部仿射变换,再通过引导图进行上采样。这篇论文实际上就是将BGU里的仿射变换操作通过网络进行学习。
BGU 主要思想
文章提出了一种加速图像处理的方法。由于很多复杂的滤镜处理速度比较慢,一个很常用的解决思路是对原图 downsample 之后做处理,然后用 upsample 得到处理结果。而在 BGU 这个例子里,利用 bilateral grid 来做 downsample - upsample 的工作,使得效果更为出色。

- 任何滤镜效果,在双边网格的局部小区域内(空域xy小范围内,以及像素域小范围内)都可以看做是一个线性变换。
- 利用 bilateral grid 可以从一个低分辨率的图上 slice 得到高分辨率的结果
- upsample 针对的是变换系数,而不是直接针对像素。这样对细节方面损失降低到最小。
具体实现步骤如下:
- 对原图 downsample 得到一个小图
- 在小图上应用滤镜
- 在小图上划分网格(bilateral graid),拟合每一个网格中的线性变换
- 线性变换的系数在网格间做平滑(这个平滑不仅在 x y 空间域的平滑,还在像素域z轴平滑,所以才要用双边网格,3D双边网格的作用就是以灰度值做第三维,将灰度差异在x轴上体现)
- 利用这个网格,根据原始大图在这个网格上做 slicing,得到高分辨率的线性变换系数,进一步得到高分辨率的结果
网络的主要结构:
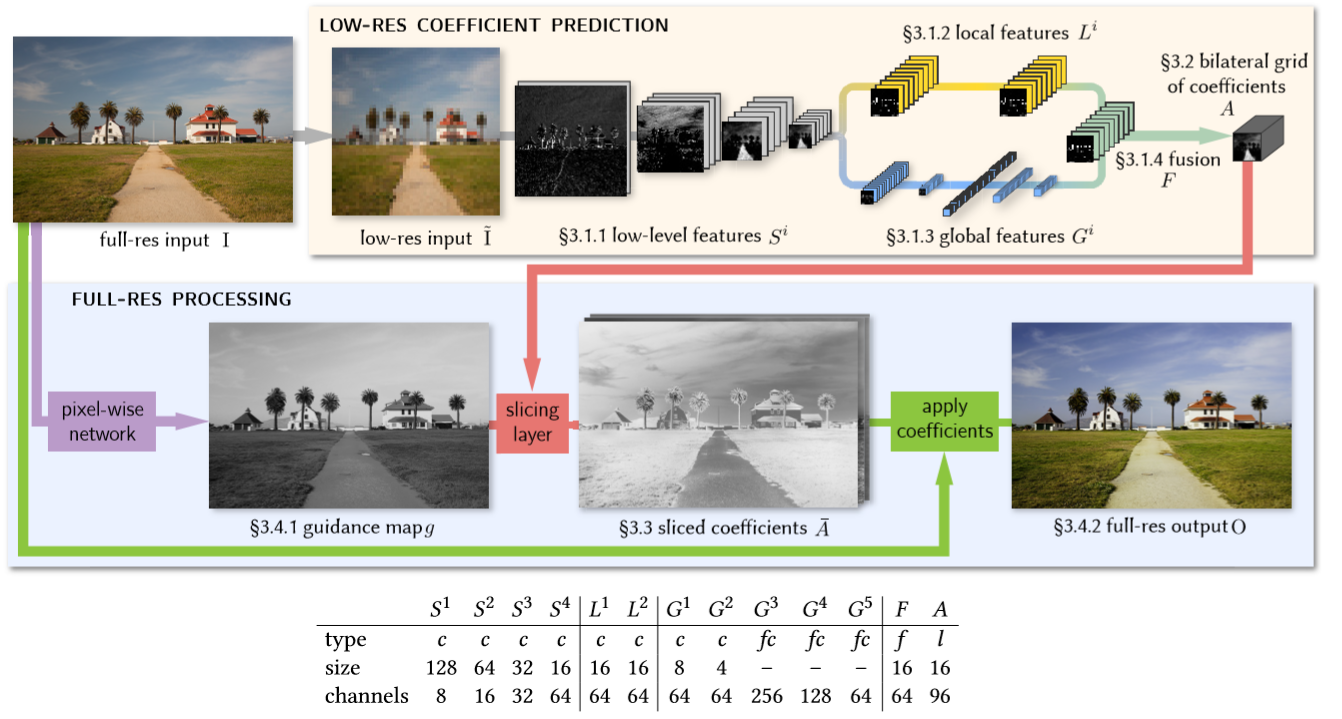
Low-level特征 首先将输入图像下采样至固定的256x256。然后一组共用的特征提取层,一共四层,每层为步长为2的3x3卷积和激活层。如果这个层数太少缺乏表达力,如下图对比,层数太多后面得到的仿射变换系数太稀疏(决定了双边网格的z轴的bin的数量)。

局部特征提取有两层卷积,这两个卷积都不改变feature map的尺寸,如果没有局部特征提取层,最后的预测的变换系数会失去空间信息。
全局特征提取 的支路包含了两个步长为2的卷积层和3个全连接层,最后输出一个包含全局信息的64维的特征向量。网络的输入图在提取特征时已经Resize成256x256了,所以可以直接用全连接。局特征具有的全局信息可以作为局部特征提取的先验,如果没有全局特征去描述图像信息的高维表示,网络可能会做出错误的局部特征表示,从而出现如上图的artifact。
两个特征融合 论文的公式没看懂,但是看代码就是将来给你个特征直接相加 接一个relu再使用卷积层将维度转换为最终的96。具体的这部分卷积的尺寸如表.
双边网格
前面CNN最终输出的尺寸 为16X16X96 96 = 3X4X8; 输出图像为3通道,对应这里的3,4是每个输出通道的每个像素需要四个系数,三个对应输入图像的三通道值和一个偏移。也就是输出图像的每个像素位置需要一个3x4的变换矩阵。那么8就代表像素域的 bin 的数量。而空间域的bin的数量由输入图像和16的比值决定的。
guide map 的 分辨率和原图一样,通道数为1 ,由原图通过几个卷积生成。
使用可训练的slicing layer进行上采样 这一步是要将上一步的信息转换到输入的高分辨率空间,这步操作基于双边网格里的slicing操作,通过一个单通道的引导图将A进行上采样。利用引导图g对A进行上采样,是利用A的系数进行三次线性插值,位置由g决定: \[ \bar{A}_{c}[x, y]=\sum_{i, j, k} \tau\left(s_{x} x-i\right) \tau\left(s_{y} y-j\right) \tau(d \cdot g[x, y]-k) A_{c}[i, j, k] \] 这里 \[ \tau(.)=\max (1-|\cdot|, 0) \]表示线性插值,\(s_{x}\) \(s_{y}\)表示网格的宽度和原图分辨率的长宽比。x 和 y 的位置由这两个长宽比决定其在网格中的对应位置,而我们知道网格z轴的 bin数量是8,应该是将z的8维度插值为 256bins 然后将bin合并成1 那么这里输出图像是 \(\bar{A}_{c}\) 的 z 轴在网格对应的深度由guide map决定 即\(\bar{A}_{c}[i,j,g[x,y]]\),这个guide map是网络可训练的,那么最后每个\(\bar{A}_{c}\) 像素的颜色深度也就由参与guide map决定,例如guide map上相邻灰度差异很大的像素,那么他们在原始网格也中映射的也是z轴上相距很远的两个bin,而BGU中说网格间是局部平滑,也即i索引的这两个变换矩阵差异会很大。但是这里是基于CNN的 并像BGU中那样直接对网格间的参数做平滑约束,这里就靠数据自己学习吧,最终学出来的也应该会有这个效果。 我感觉 它直接拿原图的灰度版本作为guide map 来指导插值也可以,但是这样相当于固定死了,原图差异多大的灰度,映射到网格中就是固定位置的bins虽然说也合理,但是 使用几层CNN来生成guide 就可学习更灵活了。这中以全分辨率的guide指导上采样 比直接使用 可学习的转置卷积上采样的对比。与基于转置卷积不同,这种方法在guide map的指导下可以很好的保留图像的边缘。

获得最终的输出
这一部分和上一部分中的guide map的计算是在全分辨率下进行的。这一步就是将上一步得到的全分辨率的变换矩阵(w x h x 12)用来对原图做变换。公式如下:
\[ \mathrm{O}_{c}[x, y]=\bar{A}_{n_{\phi}+\left(n_{\phi}+1\right) c}+\sum_{c^{\prime}=0}^{n_{\phi}-1} \bar{A}_{c^{\prime}+\left(n_{\phi}+1\right) c}[x, y] \phi_{c^{\prime}}[x, y] \]
其中 \(n_{\phi}\) = 3 表示输入图像的通道数,\(\phi_{c} = I\)表示输入图像,输出的 \(\bar{A}\) 为wxhx12的变换参数 w h 代表图像原图分辨率,12 = 3x4 按照按照 [R R R b1 G G G b2 B B B b3] 的顺序排列 R R R b1意味用于计算输出图像R通道值需要用的四个参数 且 公式中的下标按照feature 的通道序号索引的。 例如输出图像的r通道的某位置的值由 r(out)(x) = [a1, a2, a3] * [r, g, b]‘(input) + instance
损失函数
训练参考图像为人工PS的参考图像,和网络生成的图像做损失即可。由此可见损失的计算是在全分辨率下完成的。
实验
缺点,这个方法对于其他任务 例如图像去雾 ,深度估计,色彩化等任务上效果较差,这是因为其有较强的假设即输出是由输入的局部仿射变换得到的。 可以通过对输入图做特征进一步的提取特征来增强其表达效果。例如一个网格里使用36个仿射变换系数作用在一个层级为3的高斯金字塔处理的输入图要比原始的bilateral效果更好,尽管速度会变慢
….
主要类容
这篇文章将 HDR中使用到的双边滤波的思想 和 Retinex 结合,来做图像增强。首先和HDR一样,将原始降采样,在低分辨率下进行 变换参数的估计。前半部分和HDR 完全一样,包括 CNN的设计 (全局和局部特征提取,guide map的设计)。只是输出的变换参数 维度为 wxhx(9 + 9x2 + 3x4) 这里 9 + 9x2 为噪声估计用到的变换参数,9是W 9x2是偏移量,相当于可变性卷积的意思;3x4是用于光照图估计的变化参数,和HDR中的方式一样。通过两个变换分别估计出了噪声图和光照图,使用式 \(\widetilde{\boldsymbol{R}}=(\boldsymbol{I}-\boldsymbol{N}) \oslash \boldsymbol{E}\) 估计最终增强之后的图像。
网络的主要结构
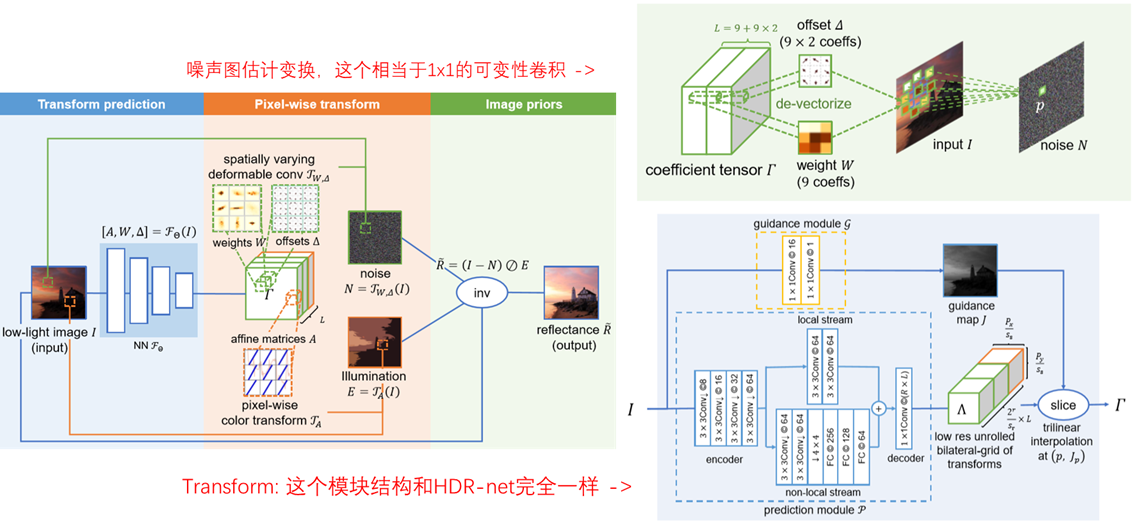
噪声图的估计
根据 变换参数对输入图像变换得到噪声估计图像,变换参数为 9 + 9 x 2 感觉相当于1X1可变性卷积。对于某个像素位置 输入为三通道 输出也为三通道,相当于需要 3x3个1x1卷积核,而 9x2 为x y两个方向上的偏移,即可变性卷积的原理。
- 最后的噪声变换 是否为 1x1的可变形卷积?
损失函数
作者使用 LOL 数据集训练 LOL 包含了 1500 low/noemal 图像对,其中500对是真实数据 其他的为合成数据。这里我饿认为LOL提供的不算参考图吧 只是 一对儿不同曝光度的图像。但是作者直接将high作为参考图像来构建损失函数。 \[ \mathcal{L}:=\mathcal{L}_{r}(\boldsymbol{R}, \tilde{\boldsymbol{R}})+\lambda_{n} \mathcal{L}_{n}(\boldsymbol{N})+\lambda_{e} \mathcal{L}_{e}(\boldsymbol{E}, \boldsymbol{I}) \] 第一项即估计的R和参考的R的相似度,具体不仅包含了衡量两个R的相似度的L1损失还有两个梯度相似度的L1损失。第二项损失用来尽量保存图像中的边缘。第三项即常规光照平滑损失。
实现细节
在训练的时候将输入图像归一化至[0,1] crop到 256x256 batch size 设置为16可变形卷积设置的K=3 Window size=15 边长缩放比例为16 32
结果