LightenNet
图像增强研究现状
基于直方图的方法:Adaptive histogram equalization and its variations
基于物理模型的方法:通常产生非自然和不现实的结果,因为一些先验或假设并不总是适用于不同的照明条件 [19, 28]
基于去雾模型的方法:去雾类方法在一定程度上可以提高微光图像的视觉质量,但这些方法缺乏有说服力的物理解释,容易产生不真实的结果。[4, 9, 28]
Such a method first inverts an input low-light image, and then employs an image dehazing algorithm on the inverted image, finally achieves the enhanced image by inverting the dehazed image.
基于稀疏表示的微光图像增强框架:增强的结果在很大程度上依赖于所学习的字典的准确性 [5]
Fotiadou et al. used two dictionaries (i.e., night dictionary and day dictionary) to transform the Sparse Representation of low-light image patches to the corresponding enhanced image patches.
基于融合的方法: 通过两个设计的权重来 融合亮度增强和对比度增强结果。此外采用多尺度融合的方法来减少放大的伪影。然而,与其他基于融合的图像增强方法一样,这种方法由于忽略了弱光照图像退化的物理特性,容易产生过增强、过饱和和不真实的结果 。 [7]
LLNet:提出了一种基于深度学习的图像自适应增强和去噪方法,直接采用了现有的深度神经网络结构(堆叠稀疏去噪自动编码器)建立低光图像与增强、去噪图像之间的关系。实验结果表明,基于深度学习的方法适用于微光图像增强。[20]
LIME: 简单的微光图像增强方法。[11]
This method first estimated the illumination of each pixel in the low-light image, then refined the initial illumination map by a structure prior, finally the enhanced image was achieved based on Retinex model using the estimated illumination map. Besides, in order to reduce the amplified noise, an existing image denoising algorithm was used as post-processing in the LIME method
LightenNet
Retinex model :
Retinex model 源自人类视觉系统研究的颜色恒常性模型(在不同光照条件下,人眼可以产生近乎一致的色彩感知)。意思是 色觉不由射入到人眼的可见光的强度决定,而是由物体的反射率所确定,人眼能够以某种方式过滤掉光照的影响而直接获得物体表面的反射率从而确定颜色 。Retinex 理论方法的发展,促进了其在图像增强中的应用。Retinex 主要用来解决数字图像中的光照不均和色偏等问题,也被广泛用于雾霾图像、水下图像等图像处理任务中以获得高对比度的图像,同时在医学、遥感、公安、交通等各个领域都有成功的应用。该模型可用表示: I(x) = R(x) · L(x) I(x)是观测到的图像, x代表像素位置,R表示该位置表面的光波长反射率, L代表该位置的光照度 反射率是物体本身固有的性质,与光照条件无关。如果能够从衣服图像中获得3个色彩通道对应的反射率R,那么从某种程度上说解读了人类视觉的恒常特性。
贡献
- 提出了一个用于低光照图像增强的简单的CNN网络。与以往的使用CNN的直接估计输出方法不同,LightenNet学习低光照图像和其响应光照强度图之间的映射。
- 基于Retinex模型,提出了一种合成低光照图像的方法。
- 提出的方法在合成低光照图和实际低光照图上都取得了最好的效果
LightenNet
通过上述,论文作者的目的通过观测图像预测其的L(x)来实现R(x) 即输入一个弱光照图像,网络通过学习到的映射输出其光照映射图,这个光照映射图接着用于获得增强的图片。
In this letter, our goal is to achieve the reflectance R(x) from the observed image I(x) by predicting its illumination map L(x)
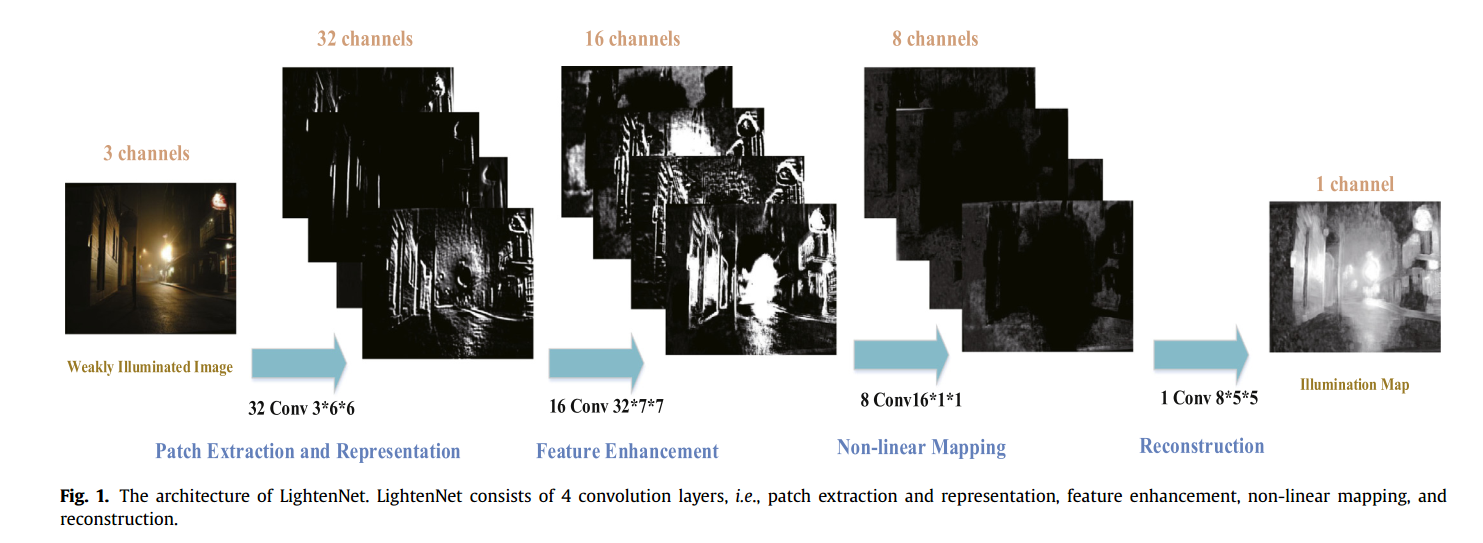
论文作者说,LightenNet包含四个卷积层,每层都有不同的作用。比如前两层主要作用于高亮度的区域,第三层作用于低亮度的区域,最后一层用于重建。
- Patch extraction and representation
- Feature enhancement :将噪声和特征分开映射
- Non-linear mapping:
- Reconstruction
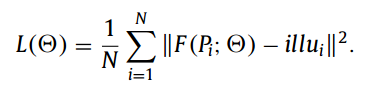
损失函数为MSE损失 illu是图像的光照图像??怎么获得?
在通过CNN获得光照映射图之后,还要进行以下3步,才能获得最终的增强图片。
Gamma矫正(Gamma correction ) L(x)` = L(x)^γ (r=1.7)
Following previous method [11], we adjust the estimated illumination map by Gamma correction in order to thoroughly unveil dark regions in the results, which can be expressed as
作者在优化CNN模型的时候认为局部的nXn输入图像具有相同的光照强度,因此gamma矫正之后需要通过指导滤波来细化光照图。在导图滤波中,将输入图像的红色通道作为导图,滤波窗口大小为16×16.
基于Retinex 模型,将低光照输入图/光照强度预测图 得到最终的增强后的输出 拥有了精确的光照强度映射图,就能产生自然的接近真实的增强输出,暗的区域得到增强,亮的区域保持不变。
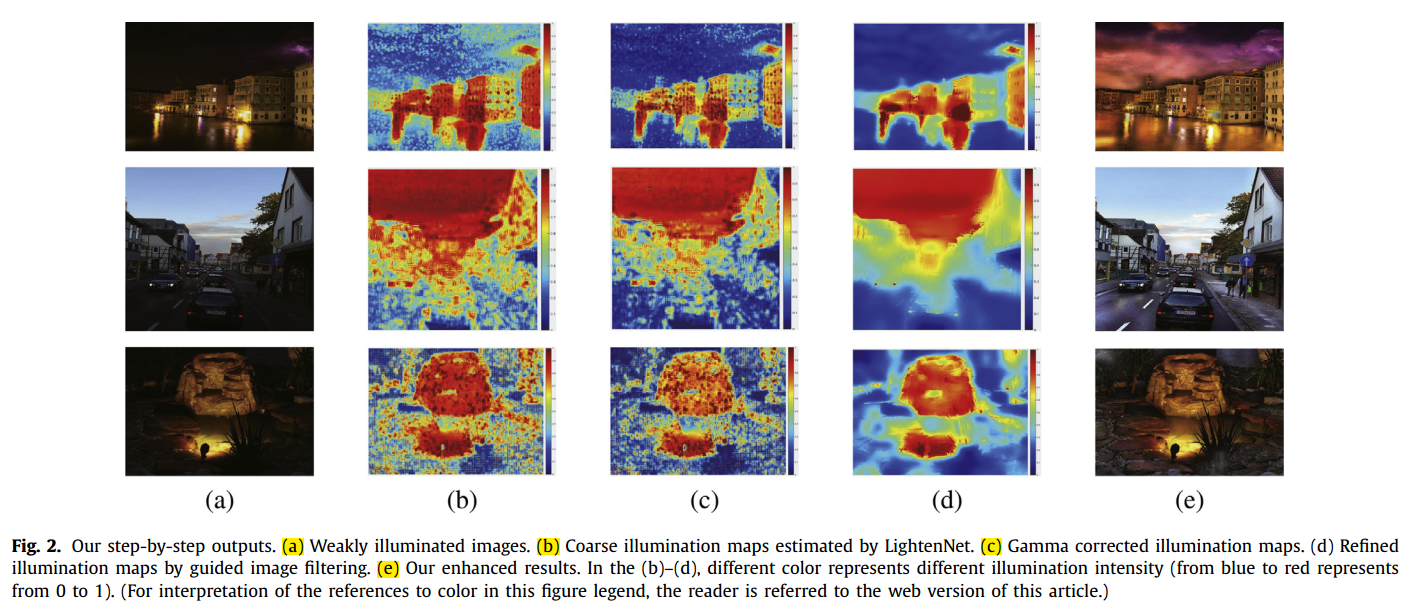
具体的实现
训练参数
- 使用高斯分布初始化权重,偏置设0
- 初始学习率0.05 每100000个迭代减少0.5
- momentum =0.9 batch_size=128
样本的合成
首先,基于图像局部亮度大小恒定的假设制造数据。作者从互联网上收集了600张带有各种内容的清晰的照明图像(光照充足且没有噪声和模糊的图),用于样本对的合成(弱光照图像以及其光照映射)。基于Retinex ,给定实际的清晰图像R(X),和一个随机光照值L, 一个弱光照图I(x) = R(x)*L 通过这种方式,获得训练图片集patch patch的overlapping pixels = 10 16X16的训练图片 2000..张 (假设输入的16X16图像具有相同的光照映射)
实验结果
- 最后的1X1的Constarint重建对这个模型很重要
- 最后尝试增加卷积层数没有作用 作者认为的原因是 1.梯度扩散效应 2.简单的原始架构重复导致网络架构不合理 作者将来会考虑使用更复杂的CNN网络来做
- Failure cases 训练的时候使用的都是没有噪声的图像,因此对于带有噪声的微光图像 效果不好
研究方向
- 使用复杂的网络
- 考虑带噪声的低光照图