内存管理
虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
分页系统地址映射
内存管理单元(MMU)管理着地址空间和物理内存的转换。 内存管理单元里的 页表 存储着 页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。 其中页面号通过 页表 转成真实 页的地址,另外,页表还有一个功能就是 标记 地址是否在内存中。具体实例如下:
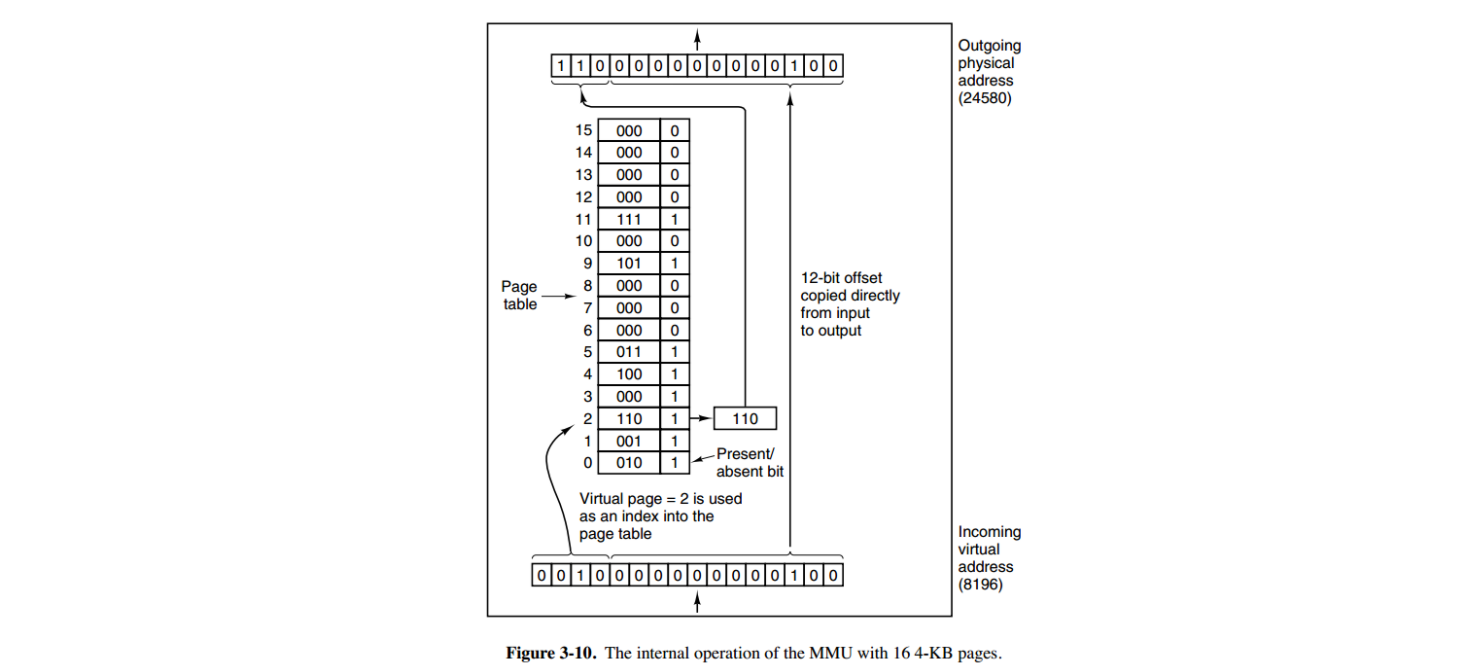
例如虚拟地址 0010 000000000100 前 4 位是存储页面号 2 后 12 位存储页面内偏移量 但是 这个页面号不是真实地址的页面号。需要通过页表映射。取页面号2即页表的第二个位置存储的 表项内容为(110 1):页表项最后一位表示是否存在于内存中,1 表示存在。则这个页对应的页框的地址为 (110 000000000100)。如果不在内存中 就将外存调入内存。
每个进程的虚拟空间地址都一样,那如果两个进程完全使用了相同的虚拟地址,页表项怎么区分呢?一个进程在执行前,操作系统要为它设置好页表寄存器,让它指向进程自己专属的页表,相当于虚拟地址 + 页表地址
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)
FIFO先进先出
FIFO, First In First Out 选择换出的页面是最先进入的页面。该算法会将那些经常被访问的页面换出,导致缺页率升高。
LRU 最近最久未使用
LRU, Least Recently Used 虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
缺点:
- 因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
- 缓存颠簸,当出现类似的 (3,2,1) 满了,然后又来连续的数据 (0,1,2,3,0,1,2,3….) 每次替换的页面都是下一次即将出现的序号,循环往复每次都要替换
- 缓存污染,当出现偶然出现的数据时,它被替换到队头,需要整个队列的长度它才会被替换出去,缓存中冷数据会存放太久
LRU-K
最久未使用K次淘汰算法 为了缓解LRU缓存污染的缺点,只有当引用次数超过K次才会被提到对头。可以使用一个队列,一个双向链表实现。对于访问次数不超过 K 次的内存页,可以将它存放在历史访问 队列里,超过K次的元素可以放在缓存队列里。
- 当历史队列中的元素满,并且还有新增访问元素的时候,将历史缓存队列的元素 按照 FIFO 的顺序置换页面(历史缓存页里的元素被访问的次数都不超过K次)
- 当历史缓存页里的某个页 访问大于等于K次时,将它从历史队列里删除,并且添加到缓存队列里。
- 当访问的元素大于K次,那么它应该在缓存队列里,缓存队列使用的双向链表实现,因此将该元素添加到队头
- 当缓存队列里的元素需要删除的时候,删除链表尾的元素, 即
第k次访问距离现在最久的那个页面。
2Q
2Q 就 类似于 LRU-2,采用一个FIFO队列 一个LRU队列,当FIFO容量为2,访问负载为 ABCABCABC时用不到 LRU队列
LFU(最不经常访问淘汰算法)
如果数据过去被访问多次,那么将来被访问的频率也更高。每个数据块一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。每次淘汰队尾数据块。
缓存颠簸
最近未使用
NRU, Not Recently Used 每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
第二次机会算法
和FIFO 一样,但是设置了第二次机会。设置一个队列保存 被置置入的 页面序号,先被置入内存的页面在队列最前面。当内存满了 需要置换页面时,fifo方法是 把队列头的 页置换出去,但是可能这个页是频繁访问的页面。第二次机会算法 是 每次访问页面是,将该页面的R位设置为 1 需要置换时,如果队列头的R位是1 就将它放放到队列最后并R位清0,再找下一个,直到队列头的页的R位为0时,将其替换掉。当每个页面都被访问过时就退化为FIFO
这种方法的缺点时 如果缓存中所有的页面都已经被标记 就退化为 FIFO
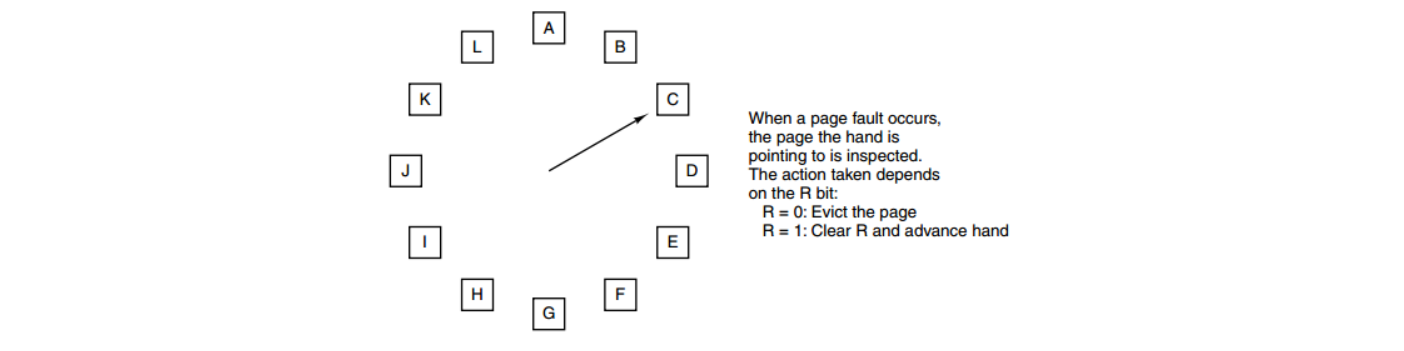
时钟
第二次机会算法中的队列 即 (链表)需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。 从C移动到D就相当于 把C放到了队列尾!!!!
分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。(代码段 …)
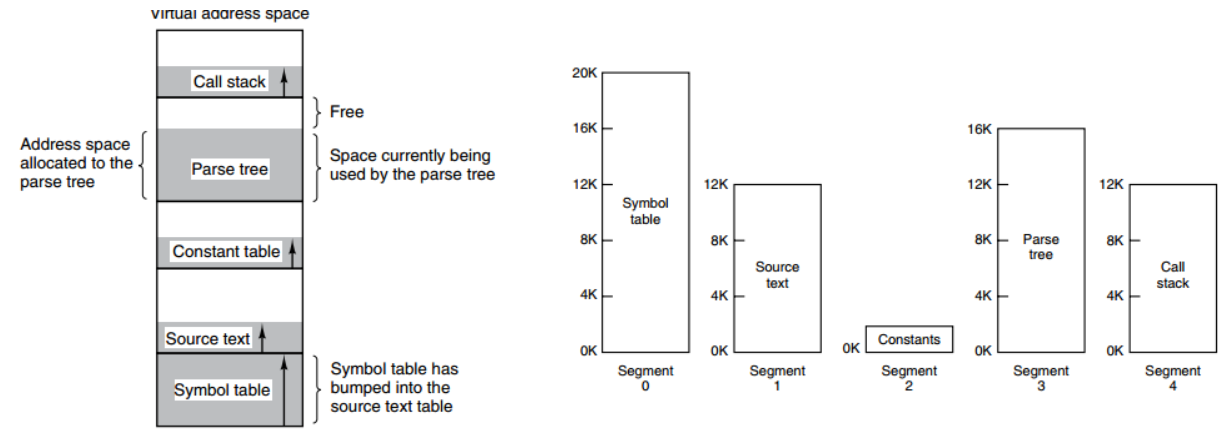
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
段页式
程序的地址空间划分成多个拥有独立地址空间的段 每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能
分页与分段的比较
- 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
- 地址空间的维度:分页是一维地址空间,分段是二维的。
- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
多级页表
一般来说,任何进程切换都会暗示着更换活动页表集。Linux内核为每一个进程维护一个task_struct结构体(即进程描述符PCB),task_struct->mm_struct结构体成员用来保存该进程的页表。在进程切换的过程中,内核把新的页表的地址写入CR3控制寄存器。
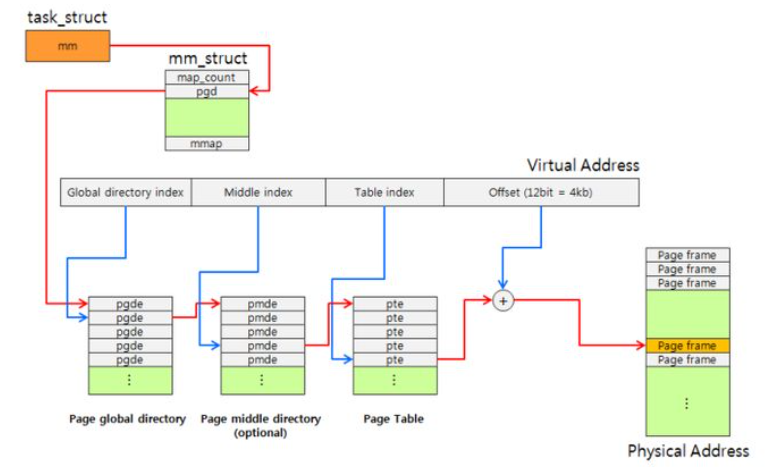
可以看出 多级页表的结构 是这样的 一级页表中的每一个项 指向下一级页表的地址。如果一级页表由 1K 个项,那么附属的就有 1K 个二级页表。
假设4G 的寻址空间,每个页大小 4K。
- 如果只用一级页表来寻址,那么需要的一级页表的项目数为 4 G / 4 K = 1 M的容量,假设表的每个项就是4字节的数组,那么存储这个1级表需要 1M X 4B = 4M
- 如果使用二级表,并且将一级表的数量设置为 1K, 那么对应的二级表的个数也为 1K 由于寻址4G空间,那么每个二级表的大小 1M / 1K = 1K ,也就是 需要1K 个 每个大小为 1K 的二级表,那么存放所有的二级表需要 1K x 1K x 4B =4M空间,加上一级表的空间 0.004M,总共需要 4.004 M 的空间存储一级和二级表。
多级页表的内存空间占用反而变大了
为什么用多级表
通过上面的计算,发现二级表占用空间反而多了。但是其实在大部分进程中,短时间内并不会真正用上 4G 的寻址空间,但是一级表由于是连续的,要加载就得全部加载进内存,尽管中间很多映射项都没用。如果使用二级表,那么一级表中只有百分之20的二级表需要存储,而没用上的二级表并不需要加载到内存,可以在使用的时候再调入。假设只用了4G寻址空间中的百分之20,二级表 需要存储的空间为 1K x 1K x 0.2 x 4B = 0.8 M 再加上一级表 1K x 4B = 0.004M 一共 使用 0.804M。即实现了分散存储 大大减少了存储页表的开支。
只有一级页表才需要总是在主存中;虚拟存储器系统可以在需要时创建,页面掉入或调出二级页表,这就减少了主存的压力;只有最经常使用的二级页表才需要缓存在主存中,这种离散的存储方式是非常便利的
page cache
基数树 主要用于构建大范围 但是有较多公共前缀的 稀疏映射关系 例如稀疏的地址集合