C++右值和左值
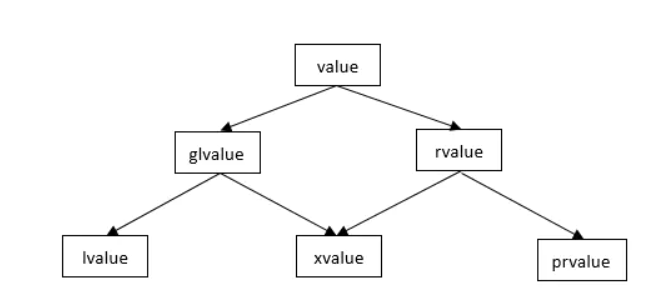
左值/右值/右值引用
左值右值的区别
左值
左值:有名字的,可以取地址的就是左值。
- 函数名和变量名
- 返回左值引用的函数调用
- 前置自增/自减运算符连接的表达式++i/--i
- 由赋值运算符或复合赋值运算符连接的表达式(a=b、a+=b、a%=b)
- 解引用表达式*p
- 字符串字面值"abc"
右值
右值:不是左值,就一定是右值。右值又分为纯右值 和 将亡值。
纯右值:指的是临时变量值、不跟对象关联的字面量值,这是C98中的定义。
除字符串字面值以外的字面值
返回非引用类型的函数调用
后置自增/自减运算符连接的表达式i++/i-- (可以理解为在 cpu 中运算产生的临时值,左值一定在内存中,右值有可能在内存中也有可能在寄存器中)
算术表达式(a+b、a&b、a<<b), 逻辑表达式(a&&b、a||b、~a)取地址表达式(&a)
将亡值:这是 C11 扩充的概念,新增的跟右值引用相关的表达式,这样表达式通常是将要被移动的对象(移为他用)。将亡值可以理解为通过“盗取”其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“盗取”的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。
- 返回右值引用的函数的调用表达式
- 转换为右值引用的转换函数的调用表达
- 举例:std::move()、static_cast<X&&>(x) (X是自定义的类,x是类对象),这两个函数常用来将左值强制转换成右值,从而使拷贝变成移动(就是浅拷贝),提高效率。
左/右值引用
左值引用就是对一个左值进行引用的类型。右值引用就是对一个右值进行引用的类型,事实上,由于右值通常不具有名字,我们也只能通过引用的方式找到它的存在。
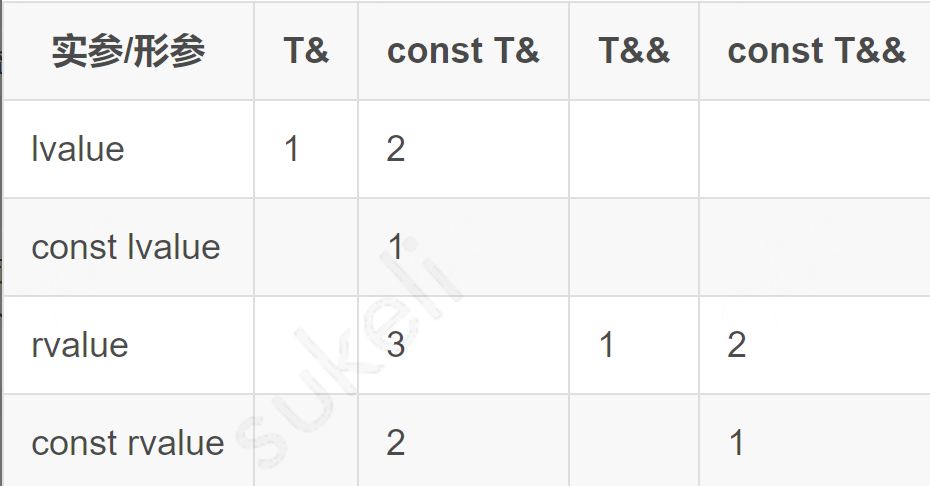
左值引用通常只能绑定到左值,不能绑定到右值,但是常量左值引用 是个万能的应用类型,它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“余生”中只能是只读的,因此优先使用右值引用去绑定右值,这样被绑定的右值也可以被修改。
1 | int &a = 2; // 左值引用绑定到右值,编译失败 |
右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要std::move()将左值强制转换为右值,例如:
1 | int a; |
引用重载优先级
1 | void f(Data& data); // 1, data is l-ref |
同理,由于常引用既可以绑定到左值,又可以绑定到右值 (但是不能修改绑定的右值),因此:
1 | void g(const Data& data); // data is c-ref 即可以接受左值 又可以接受右值 |
但是C++ 对引用参数的重载也有优先级,在 对于传入的右值,优先选择右值引用的形参列表,而不是常引用,具体如下:
1 | void f(const Data& data); // 1, data is c-ref |
针对不同左右值 实参 (argument) 重载 引用类型 形参 (parameter) 的优先级如下。(数值越小,优先级越高;如果不存在,则重载失败)
引用折叠
既然有了 左值引用 和 右值 引用,那么 将两种引用排列组后 就可以得到四种组合,但是最终确定变量的引用类型只可能是左值引用或右值引用,所以引用折叠的目的就是根据 一定的规则 将引用简化。
- 规则:如果任一引用为左值引用,则结果为左值引用。否则(即两个都是右值引用),结果为右值引用。
1 | - 左值-左值 T& & |
但是, 在编译器中编写以下代码,是会报错的:
1 | // ... |
编译器不允许我们写下类似int & &&这样的代码,但是它自己却可以推导出int & &&代码出来。它的理由就是:我(编译器)虽然推导出T为int&,但是我在最终生成的代码中,利用引用折叠规则,将int & &&等价生成了int &。推导出来的int & &&只是过渡阶段,最终版本并不存在。所以也不算破坏规定咯。
通用引用
所谓的万能引用并不是C++的语法特性,而是我们利用现有的C++语法,自己实现的一个功能。因为这个功能既能接受左值类型的参数,也能接受右值类型的参数。所以叫做万能引用。有两个必要的条件:
- 必须满足
T&&这种形式 - 类型
T必须是通过推断得到的
所以,在我们完美转发这个部分的例子当中,我们所使用的这种引用,其实是通用引用,而不是所谓的单纯的右值引用。因为我们的函数是模板函数,T的类型是推断出来的,而不是指定的。那么相应的,如果有一段这样的代码:
1 | template <typename T> |
上面的这个T是不是通用引用呢?答案是不是。因为当这个类初始化的时候这个T就已经被确定了,不需要推断。所以,可以构成通用引用的有如下几种可能:
- 函数模板参数(function template parameters)
auto声明(auto declaration)typedef声明(typedef declaration)decltype声明(decltype declaration)
通用引用的特点是 : 传进来的如果是左值引用那就是左值引用,如果是右值引用那就是右值引用。
通用引用原理
总结上面的结论。编程的时候,编译器不允许显式的出现重叠的引用情况,但是在需要编译器推断类型的场景,可以重叠引用,编译器会根据折叠引用规则简化为最终的 左/右值引用。应用这个特性,从而可以实现通用引用的功能。
1 | template<typename T> // 一个通用引用的例子 |
1 |
|
上例子中,当传入左值时,param 最终为左值引用,编译器会将 T 推导为左值引用的类型(详情模板推导的规则),替换后 变为 int& && 最终就是左值引用,所以它能接受一个左值。当传入的就是左值引用类型时,int& && 还是左值引用,当传入的是右值 int && && 最终还是右值引用,即万能引用,既可以传入 左值/右值/左值引用/右值引用(右值引用实际就是左值了,所以如果传入的是右值引用,因为右值引用有了具体的名字,它实际也是一个左值了,在传入这个函数,进来就是左值了,这就不符合完美转发的要求)
右值引用的目的
语义移动
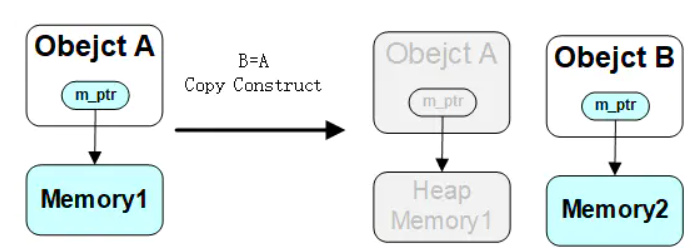
传统的拷贝构造函数的入口参数为 常左值引用
1 | class string { |
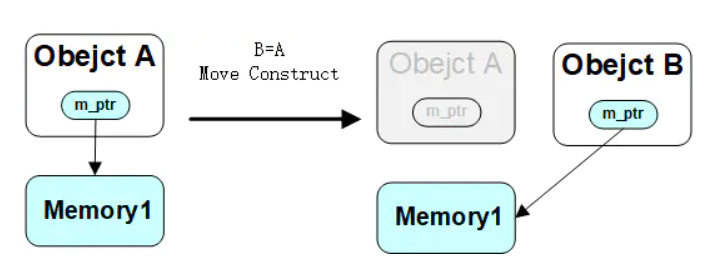
问题:上述例子中 get_string 返回的是临时右值,如果不存在 移动构造函数,会调用类别的拷贝构造函数,将临时右值中内存区域的东西在内内拷贝出另一份,然后再把临时右值的内存释放掉。但是如果存在 移动构造函数,会被优先重载(入口参数为右值引用),那么在移动构造函数中,只是将临时右值的内存转给了类管理。这样并没有重新拷贝内存,实际也没有释放掉临时右值,它被右值引用延长了生命周期。这两种函数的对比如下图:
完美转发
例子:
1 | template <typename T> |
在这个例子当中,我们的期待是,我们在main当中调用relay,Test的临时对象作为一个右值传入relay,在relay当中又被转发给了func,那这时候转发给func的参数t也应当是一个右值。也就是说,我们希望:当relay的参数是右值的时候,func的参数也是右值;当relay的参数是左值的时候,func的参数也是左值。
但是结果与我们预想的似乎并不相同:
1 | default constructor |
我们看到,在relay当中转发的时候,调用了复制构造函数,也就是说编译器认为这个参数t并不是一个右值,而是左值,因为它有一个名字。那么如果我们想要实现我们所说的,如果传进来的参数是一个左值,则将它作为左值转发给下一个函数;如果它是右值,则将其作为右值转发给下一个函数。
这时,我们需要std::forward<T>()。与std::move()相区别的是,move()会无条件的将一个参数转换成右值,而forward()则会保留参数的左右值类型。所以我们的代码应该是这样:
1 | template <typename T> |
1 | default constructor |
而如果我们的调用方法变成:
1 | int main() { |
那么输出就会变成:
1 | default constructor |
完美地实现了我们所要的转发效果。但是这个例子中,t 明明是左值,为何可以传入右值引用的函数中?这里的 void relay(T&& t)其实是通用引用,即通过上面的引用折叠规则 由编译器推断得出的。
完美转发原理
std::forward的源码形式大致是这样:
1 | /* |