KinD
主要贡献
- 总结了微光图像增强中存在的挑战:
- 如何有效的从单张图像中估计光照,并且可以灵活的调节光照等级
- 如何去除之前隐藏在黑暗中的噪声和颜色失真等退化现象
- 在没有充足的训练样本和完美的ground-truth的情况下训练低光照增强网络模型
- 和RetinexNet模型类似:
- 基于Retinex理论 使用网络将图片分解为两个部分:光照和反射率
- 网络的训练是基于一对低光照正常光照图像,而不是使用反射率和光照groundtruth
- 提供了一个光照映射图可以调节的 灵活的调节网络 以供不同的需求
- 提出了一个可以有效消除由于光照增强放大的暗区域噪声的模块
研究现状
Plain Methods: 基于直方图均衡化的方法,gamma矫正的方法。这类方法缺点是很少考虑光照因素 Traditional Illumination-based Methods : 传统基于光照的方法。例如SSR MSR NPE等,通过调整图像光照来增强,这类方法通常没有考虑色彩失真和噪声。 基于深度学习的方法:
论文理论
主要思想
没有完美的光照图和反射率图,因此需要根据各种约束条件来优化分解网络。作者认为,微光图像中的噪声在暗区域较亮区域的影响更大,因为暗区域的微小噪声和颜色失真会一起被放大,所以作者认为用光照图来指导反射率图去噪重建效果会比直接用DBM3无差别的对反射率图去噪好。最后,作者认为正常微光图像的退化程度相对于正常光照图片要严重,这些退化的因素会随着反射率图最终传递到最后的结果,因此作者认为可以使用正常图像分解产生的反射率图作为低光照图分解的反射率图重建(去噪,颜色矫正等)的指导。作者申明这种使用良好的反射率图做指导和直接使用原图做指导完全不同。
光照图指导的反射率重建:
\[ \mathbf{I}=\mathbf{R} \circ \mathbf{L}+\mathbf{E}=\tilde{\mathbf{R}} \circ \mathbf{L}=(\mathbf{R}+\tilde{\mathbf{E}}) \circ \mathbf{L}=\mathbf{R} \circ \mathbf{L}+\tilde{\mathbf{E}} \circ \mathbf{L} \]
I为输入低光照图,R为本身的反射率图,L为原本的低光照图。如果将图像分解,会将噪声分解到\(\tilde{\mathbf{R}}\) 此时包含(R + E)因此最后调整光照强度再还原时,E与L一起被放大,因此需要用L来指导去噪。那么为什么不直接从输入微光图像I中去除E呢?一方面光照不平衡的问题存在,另一方面内部的细节和噪声不均匀地混合在一起,再就是由于L 的存在是个变量,没有合适的方法去掉,就是同一个场景光照不同噪声强度也不同,难以在参杂一个光照变量的情况下很好的去除噪声,而反射率图就更纯粹,比较适合用来去噪。
Kind Network
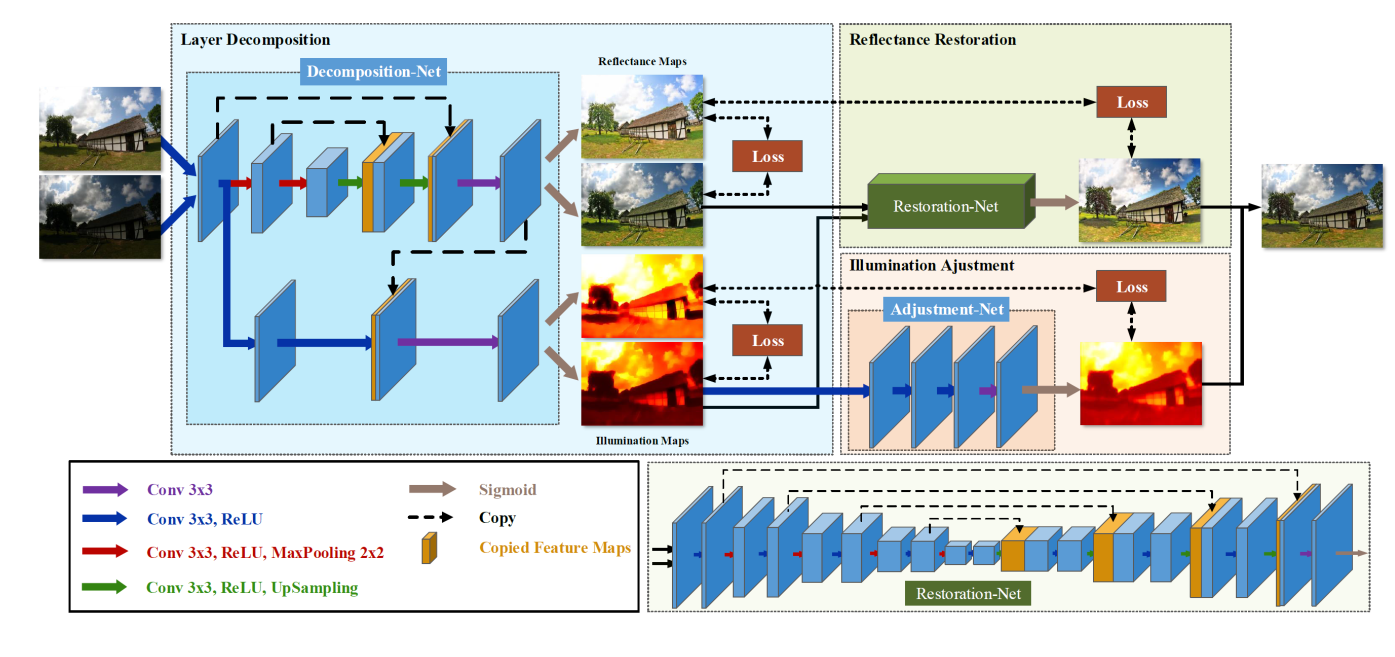
分解网络
训练时网络有输入成对的图像 Il Ih
- 保证输入的低光照和正常光照图像分解产生的反射率图相同:
\[ \mathcal{L}_{r s}^{L D}:=\left\|\mathbf{R}_{l}-\mathbf{R}_{h}\right\|_{2}^{2} \]
- 光照图平滑约束,其中\(\nabla\)表示梯度。max( \(\epsilon\))避免分母除0 这里是通过输入图像的梯度加权光照梯度的,而Retinex中是通过反射率图加权。可以看出,输入图像边缘处梯度大,光照图对应的梯度损失小,允许此处的光照分布不那么平滑。
\[ \mathcal{L}_{i s}^{L D}:=\left\|\frac{\nabla \mathbf{L}_{l}}{\max \left(\left|\nabla \mathbf{I}_{l}\right|, \epsilon\right)}\right\| 1+\left\|\frac{\nabla \mathbf{L}_{h}}{\max \left(\left|\nabla \mathbf{I}_{h}\right|, \epsilon\right)}\right\| \]
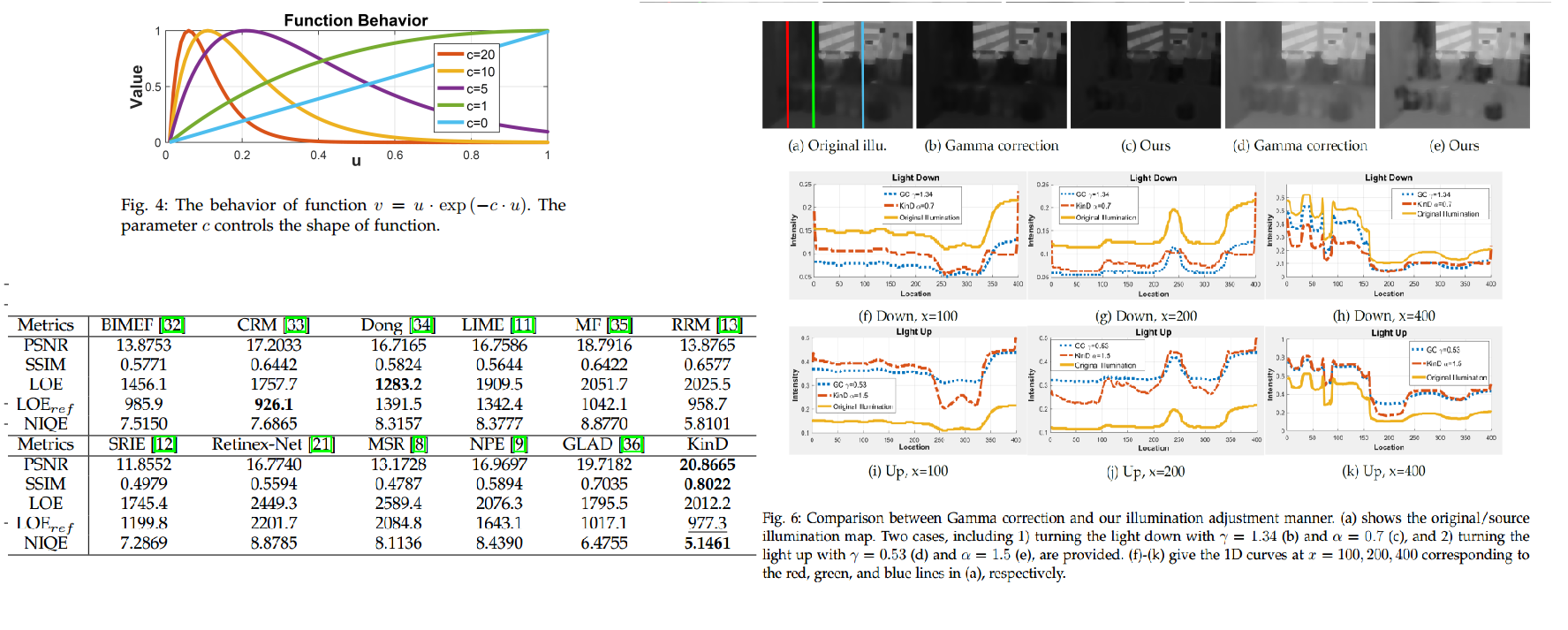
- 底/高输入图像的低/高光照图的结构一致性。作者给出了uexp(-cu)的变化曲线,先增后减。大概意思是,如果两个光照图的梯度都很大或者都很小,输出loss很小,如果一大一小则loss很大,也符合这个函数的变化规律。 ??
\[ \mathcal{L}_{m c}^{L D}:=\|\mathbf{M} \circ \exp (-c \cdot \mathbf{M})\|_{1} \text { with } \mathbf{M}:=\left|\nabla \mathbf{L}_{l}\right|+| \nabla \mathbf{L}_{h} \]
- 将分解产生的结果要能尽可能还原回原输入图
- $ _{h} $
\[ \mathcal{L}_{r e c}^{\hat{L} D}:=\left\|\mathbf{I}_{l}-\mathbf{R}_{l} \circ \mathbf{L}_{l}\right\|_{1}+\left\|\mathbf{I}_{h}-\mathbf{R}_{h} \circ \mathbf{L}_{h}\right\|_{1} \]
- 最后将上述损失按权重相加即可 0.01,0.08,0.1,1
反射率重建网络
该部分在Deep RetinexNet中使用的DBM3去噪,然后和光照调整网络整合出输出结果。而在改论文中使用了Unet类似的编解码网络重建。输入为 低光照图分解产生的 R 和 I 。I 用来指导R的重建,高质量图产生的R作为groundtruth来计算损失。同样的 把纹理细节也计入了损失。 \[ \mathcal{L}^{R R}:=\left\|\hat{\mathbf{R}}-\mathbf{R}_{h}\right\|_{2}^{2}-\operatorname{SSIM}\left(\hat{\mathbf{R}}, \mathbf{R}_{h}\right)+\left\|\nabla \hat{\mathbf{R}}-\nabla \mathbf{R}_{h}\right\|_{2}^{2} \]
亮度调整网络
计算两个光照图之间的关系的方法为:ta = mean(L1/L2) 在网络训练是可以以低光照图作为输入待调整,高光照亮度图作为groundtruth 同时计算二者的调节系数a 并扩充为一个featuremap一起输出网络。最后的损失为: \[ \mathcal{L}^{I A}:=\left\|\hat{\mathbf{L}}-\mathbf{L}_{t}\right\|_{2}^{2}+\left\||\nabla \hat{\mathbf{L}}|-\left|\nabla \mathbf{L}_{t}\right|\right\|_{2}^{2} \]
实验结果
主要在LOL数据集上对比和各种算法。包含500对正常/低光照图像。分解网络batchsize=10, path-size=48X48。分辨率重建网络和光照跳着网络batch size为4,384X384大小。SGD优化
后续版本 KindD ++

主要是改进了 重建网络 光照图深入重建网络的各个层 ,且重建网络中使用多尺度的卷积contact
本文的创新点在于:
- 将光照图作为反射率图去噪重建的指导
- 光照图的光照强度可调整功能
- 分解网络中 对光照强度的梯度平滑中的权重 感觉较RetinexNet网络的好
- 将正常光照的反射率图作为低光照图反射率图去噪调整的groundtruth
感觉的缺点:
- 分解网络结构
文章复现遇到的问题
- 在使用LOLDateset数据集时, 一定要注意正常光照图和低光照图成对儿 LOLDatesat数据中 高低光照图的名字是一样的,但是两个文件夹中 低光照的图片不一定能在高光照文件夹中找到对应名字的图 这种图应该舍去 一开始读取数据的方法是排序后取相同位置的图片做一对儿 这样不行 因为有漏序号的 后面就都错位了
- 分解网络 论文给的详细网络结构没有BN层 不能加BN层!!!!! 一开始以为BN层只有好处没坏处 结果加了死活不能收敛
- 在批量训练时 有时候在每个epoch最后一批 Loss可能会跳 可能因为 总的训练样本数量 / batch_size 不能整出 dateloader 中 drop_last = True 舍弃最后一批
- 原版本的用2X2卷积计算的梯度,这种偶数的卷积核在边界会补0 但是计算完后没有把补0的边界填充0 会有白边,这不影响,在加上规范化后,由于百边的影响会使整体的梯度幅值偏小。所以复现时不用卷积算梯度后补0 整体梯度比用卷积算的大0.02左右 梯度整体偏大会使光照图区域灰色的一片....
关于分解网络损失权重的讨论
按照原始的损失权重的定义 结果

可以看出 网络映射成了恒等映射, 分离出来的光照分量恒为1 这种情况,重建损失很低,但是R的相似度也很低,但是由于其权重只有0.01 所以被削弱了。感觉不符合分解的目的。
rec, rs, is, mc = 1,1,0.08,0.1

可以看出增R反射率损失的权重
官方代码
与论文描述不一致的地方
- 激活函数使用的是 lrelu 斜率为0.2
- 对梯度进行了去均值归一化 先归一化再数据扩增 还是先扩增再归一化 有区别? 程序错误没有裁剪 patch !!!!!!
- 分解网络equal_r 损失为L1损失而 文章中为平方MSE损失
- 分解网络中 mc损失 x y 分别计算reduce平均求和 权重0.15 加权TV损失权重为0.2
别人的笔记
Kindling the Darkness: A Practical Low-light Image Enhancer
paper:Kindling the Darkness: A Practical Low-light Image Enhancer
Abstract
- 类似Retinex理论,将图片分解为2部分。
- 一部分用于光照调整(illumination)
- 另一部分用于degradation removal(reflectance)
- 原始空间被解耦为2个子空间,以便学习
- 网络是用成对的不同曝光条件的图像去训练,而不是用reflectance and illumination的GT
Introduction
一些操作在一些环境上可以用于调整图像的质量,但也存在缺点。比如,高ISO虽然增加了图像传感器对光的敏感度,但是噪声也放大了,因此造成了低信噪比SNR。长曝光受限于拍摄静态场景,否则图像会变得模糊。使用闪光灯虽然可以照亮环境,但会带来意想不到的高光和不平衡的光线,视觉效果不太好。
3种不好处理的光条件:
- 极度低光,一些噪声和颜色失真隐藏在黑暗中。
- 在日落拍摄的照片,物体在逆光下受影响。
- 中午对着光源拍照也比较难处理
low-light image增强没有真实数据的GT,因为每个人喜欢的light level是不一样的,所以没人可以说什么光条件就是最好的。
作者总结了low-light image enhancement的challenges 有以下几点:
1.如何有效的从单张图像中估计出光照图成分,并且可以灵活调整光照level?
2.在提升图像亮度后,如何移除诸如噪声和颜色失真之类的退化?
3.在没有ground-truth的情况下,样本数目有限的情况下,如何训练模型?
1.1 Previous Arts
(1)Plain Methods:
处理在全局低光照的图像的比较直观的方法是放大图像,但会在细节上有噪声和颜色失真。
在颜色较亮的区域,放大操作经常会导致颜色过饱和以及过度曝光。
直方图均衡化(histogram equalization,HE),试图把值映射在[0,1],平衡输出的直方图来解决这个问题。
伽马矫正(gamma correction,GC),以非线性的方式在每个像素执行。虽然GC可以对暗像素进行提亮,但没考虑每个像素之间的相邻关系。
这些普通方法的缺点是,不考虑真实光照因素,导致增强的效果不好,与真实场景不同。
(2)Traditional Illumination-based Methods:
与plain method不同的是,传统的基于光照的方法注意到光照的重要性。
Retinex理论:有颜色的图片可以被分解为2部分,反射率和光照。
比较早提出理论有:
- single-scale Retinex,SSR
- D. J. Jobson, Z. Rahman, and G. A. Woodell, “Properties and performance of a center/surround retinex,” IEEE Transactions on Image Processing, vol. 6, no. 3, pp. 451–62, 1997.
- multi-scale Retinex,MSR
- D. J. Jobson, Z. Rahman, and G. A. Woodell, “A multiscale retinex for bridging the gap between color images and the human ob- servation of scenes,” IEEE Transactions on Image Processing, vol. 6, no. 7, pp. 965–976, 2002.
这些方法生成的结果通常不真实,且在有的地方过度增强。
之后又有一些方法进行改进:
- NPE:在增强对比度的同时保护自然光照。
- D. J. Jobson, Z. Rahman, and G. A. Woodell, “A multiscale retinex for bridging the gap between color images and the human ob- servation of scenes,” IEEE Transactions on Image Processing, vol. 6, no. 7, pp. 965–976, 2002.
2.通过融合最初光照估计的多重推导来进行调整光照。
- X. Fu, D. Zeng, H. Yue, Y. Liao, X. Ding, and J. Paisley, “A fusion- based enhancing method for weakly illuminated images,” Signal Processing, vol. 129, pp. 82–96, 2016
- 缺点:有时会牺牲真实区域的丰富纹理。
3.从初始光照图估计结构光照图。
- X. Guo, Y. Li, and H. Ling, “Lime: Low-light image enhancement via illumination map estimation,” IEEE Trans Image Process, vol. 26, no. 2, pp. 982–993, 2017
- 缺点:假设图像是无噪声和无颜色失真的,没有考虑到退化问题
4.提出权重变分模型同时估计反射率和光照估计(SRIE),通过调整光照生成图像
- X. Fu, D. Zeng, Y. Huang, X. Zhang, and X. Ding, “A weighted variational model for simultaneous reflectance and illumination estimation,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 2782–2790, 2016
5.在3的基础上提出了引入了an extra term to host noise
缺点:4、5虽然可以处理图像的弱噪声,但不擅长处理颜色的失真和强噪声。
(3)Deep Learning-based Methods
- LLNet(low-light net),建立深度模型作为同时处理对比度增强和去噪的模块。
- K. G. Lore, A. Akintayo, and S. Sarkar, “Llnet: A deep autoen- coder approach to natural low-light image enhancement,” Pattern Recognition, vol. 61, pp. 650–662, 2017.
- MSR-net,作者认为多尺度Retinex等价于前向传播的不同高斯卷积核的卷积网络,受此启发,构造了end-to-end的网络结构,直接学习从dark到bright。
- L. Shen, Z. Yue, F. Feng, Q. Chen, S. Liu, and J. Ma, “Msr-net:low- light image enhancement using deep convolutional network,” p. arXiv, 11 2017.
- Retinex-Net,集成了图片分解和光照映射,此外,还利用了现成的(off-the-shelf)去噪工具(BM3D)to clean the reflectance component
- C. Wei, W. Wang, W. Yang, and J. Liu, “Deep retinex decom- position for low-light enhancement,” in British Machine Vision Conference, 2018.
- (ps:不懂to clean the reflectance component)
这些方法的缺点:
1.这些方法都假设每个图像都存在GT的光,没有考虑到不同光的噪声在不同的区域的影响不同。即,提取了光照因子后,reflectance的dark区域的噪声level明显高于bright区域。在这种情况下,训练均匀分布图像(反射率)的去噪器不再适合。
2.此外,这些方法都没处理好颜色失真的退化问题。
- 提出处理低光照的end-to-end的pipeline,用fully convolutional network同时处理噪声和颜色失真
- C. Chen, Q. Chen, J. Xu, and V. Koltun, “Learning to see in the dark,” in IEEE Conference on Computer Vision and Pattern Recogni- tion, pp. 3291–3300, 2018.
- 缺点:
- 只适用于raw数据,应用场景受限
- 如果将网络改造成输入JPEG格式,性能会变差
现有的方法都是通过伽马矫正调整光照,在精心构造的训练数据中指定一个level或者融合。伽马矫正可能无法反应不同曝光level之间的关系。第二种方法受限于指定的level是否包含在训练数据中。而最后一个方法,甚至没有提供可操作的选项。(这里不是太懂)
因此,需要设计一个映射函数,将one light(exposure)转换为another以便用户调整。
(4)Image Denoising Methods:
经典的方法是用特定的先验来处理图像,比如:non-local self-similarity、piecewise smoothness(分段平滑)、信号稀疏表示。最受欢迎的可能是:BM3D和WNNM。
- BM3D:
- K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Transactions on Image Processing, vol. 16, no. 8, pp. 2080–2095, 2007.
- WNNM:
- S. Gu, L. Zhang, W. Zuo, and X. Feng, “Weighted nuclear norm minimization with application to image denoising,” in IEEE Con- ference on Computer Vision and Pattern Recognition, pp. 2862–2869, 2014.
缺点:
由于优化具有高复杂性以及参数的搜索空间很大,这些传统方法在真实条件下效果不是很好。
基于深度学习的去噪器表现出优越性。比如:
- SSDA,使用堆叠的稀疏自动编码器
- F. Agostinelli, M. R. Anderson, and H. Lee, “Adaptive multi- column deep neural networks with application to robust image denoising,” in NeurIPS, 2013
- J. Xie, L. Xu, and E. Chen, “Image denoising and inpainting with deep neural networks,” in NeurIPS, 2012.
- TNRD,by trainable nonlinear reaction diffusion(反应扩散?不是很懂)
- Y. Chen and T. Pock, “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1256–1272, 2017.
- DnCNN,使用残差学习和batch normalization,可以节约计算成本,因为在测试阶段只有后馈卷积操作。
- K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142–3155, 2016.
缺点:
这些模型在blind image denoising上仍然有困难。one may train multiple models for varied levels or one model with a large number of parameters,这是很不灵活的
通过在任务汇总反复思考,这个问题得到了一定的缓解:
- paper:
- X. Zhang, Y. Lu, J. Liu, and B. Dong, “Dynamically unfolding recurrent restorer: A moving endpoint control method for image restoration,” in ICLR, 2018.
缺点:
上面提到的方法都没有考虑到不同的区域有着不同的level的噪声。
同样的问题也出现在颜色失真上。
1.2 Contributions
- 受到Retinex理论启发,提出的网络将图像分解为2个部分:反射率和光照,将原始空间解耦为2个更小的空间
- 网络的训练数据是在不同光照/曝光条件下获取的成对图像,而不是用任何的GT的反射和光照信息
- 提供了一个映射函数方便用户根据不同需求调整光线level
- 提出的网络也包括了一个可以有效消除放大黑暗区域带来视觉缺陷的模块
2、Methodology
一个理想的低光度图像增强器应该可以有效去除藏在黑暗中的退化,以及灵活地调整光照/曝光条件。
网络结构:

- 整个网络有2个分支,分别是:反射率和光照
- 从功能的角度可分为3个部分:
- 层分解(layer decomposition)
- 反射率恢复(reflectance restoration)
- 光照调整(illumination adjustment)
2.1 Consideration & Motivation
(1)Layer Decomposition
Retinex 理论:一个图像I可以看做是2个部分,reflectance R和illumination L,即,I = R ◦ L,R和L的对应元素的点乘。
(2)Data usage and Priors
层分解在自然界是欠定的,因此额外的先验/正则化很重要。假设图像的无退化的,一个场景的不同镜头应该有相同的反射率。光照图虽然有很大不同,但应该有简单且一致的结构。(不懂这里)
在真实场景下,低光度图像的退化一般要比亮图像更严重,此时转移为反射率部分。(这里不懂)
由此得出,亮光图像的反射率可以作为GT,给退化的低光度图像学习恢复。
为什么不用合成图像?因为难以合成,退化不是简单的组成,在不同的传感器上会有不同的变化。
作者提到,使用(well-defined)的反射率完全不同于用亮光图像作为低光图像的参考。
(3)Illumination Guided Reflectance Restoration
在分解的反射率中,较暗光线的污染要比亮光的区域严重。在数学层面上,一个退化的图像可以被表示为:
I = R ◦ L + E
E:表示污染成分
反射率恢复不能被均匀地处理整个图像,关照图可以作为一个好的向导。
为什么不直接从输入I中去掉噪声E?
一是不均衡的问题仍然存在,内在细节被不平均地与噪声混淆,二是与反射率不同,因为L是不同的,没有合适的参考给退化去除。颜色失真也是一样。
(4)Arbitrary Illumination Manipulation(任意光照调整)
最好的光照强度对不同的人和应用是很不同的,因此,需要提供任意调整光照的接口。
过去常用的3个方法,fusion,缺少光线调整;light level appointment,要求训练集包含目标level;伽马矫正,不能反映不同光线(曝光)level之间的联系。
作者提出从真实数据中学习灵活的映射函数,用户可以随意调整level
2.2 KinD Network
网络结构:
(一)Layer Decomposition Net
- 输入:用不同光照/曝光的图像作为成对图像[I_l,I_h]
- 之前有个假设,在相同的场景,反射率应该相同,首先的目标是让反射率对[R_l,R_h]应该尽量相同(图中上面的中间输出)。(理想情况下无退化情况)。
- 光照图[L_l,L_h]应该分段平滑,且相同(图中下面的中间输出)。
- 定义各种loss
- reflectance similarity,L_rs,反射率相似度
- 即,输出的两张反射率map的相似度
- illumination smoothness,L_is,光照平滑度
- 即,输出的两张光照map的平滑度
- 衡量光照相对输入来说的结构相关性(这里不懂)
- 这个平滑项对边缘的像素惩罚小,对平滑区域惩罚大。
- mutual consistency,L_mc,相互一致性
- 保证强相关的边缘被保留下来
- 即,两张光照map之间
- reconstruction error,L_rec
- 衡量重建图像的误差
- 即,分辨率图和光照图各自的生成和各自的输入之间的误差
- reflectance similarity,L_rs,反射率相似度
(二)Reflectance Restoration Net
低光照图像比亮光度图像更多退化。
思路:将清晰的反射图作为GT
loss:L_RR
degradation分布在反射率上是复杂的,强依赖于光照分布,所以作者将光照信息和退化反射率一起引入图像恢复中。
(三)Illumination Adjustment Net
通过光强率α控制,α=mean(L_t/L_s),这里的除法是对应元素相除。
α可以作为一个指标,用于将L_s训练到L_t,(L_t是目标源光),α>1表示低光到高光。
3个conv (2个conv+ReLu)+ 1个sigmoid
α被扩展为一个map,作为输入的一部分。
Loss:L_LA
总结
- 输入是成对的不同曝光的图像
- 将亮光图像的反射率作为GT,明亮图像的反射图作为GT去引导低照图像的反射图进行增强
- 定义了一堆loss(个人觉得过于繁琐,不优雅,且排版emmm)