python爬虫入门
HTTP / HTTPs协议
总的来说 当访问一个网站时,浏览器会发送很多请求,然后服务器依次根据请求内容返回,返回的内容里包含了需要的信息。谷歌浏览器 F12 开发者模式 可以观察到浏览器发出的所有请求。
基本流程
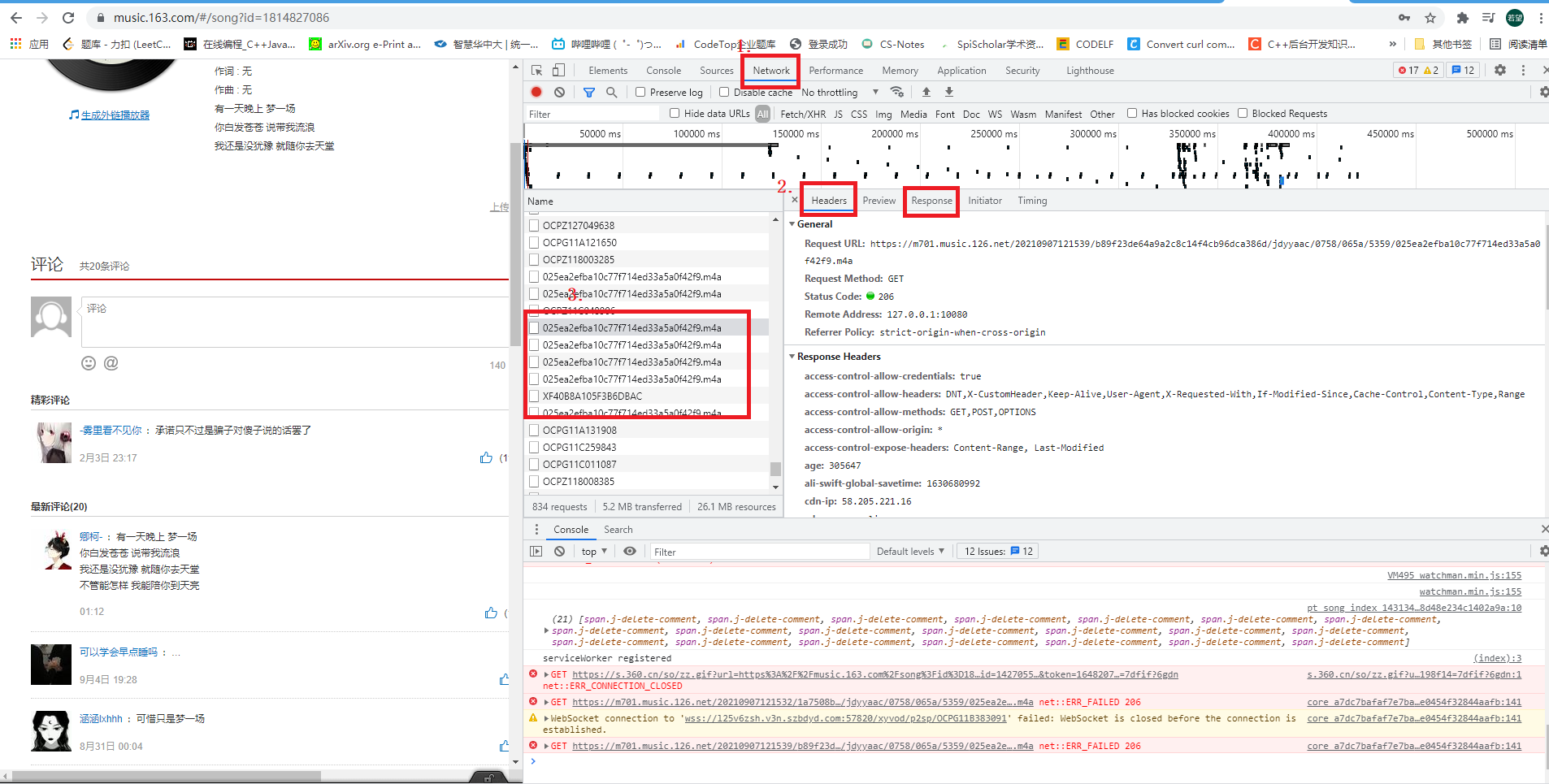
主要有三个地方需要观察
- Networks:选中该项,然后查看浏览器发出的所有的请求
- 仔细查看所有请求,并看他对应2位置的 response 响应
- 例如如果是要 爬取 视频/音频,如果该条请求响应的文件应该很大,且 response 显示的乱码的信息,该条请求极有可能请求的就是视频/音频的 指令
- 例如如果想要的 爬取的东西是 文字,那么在response 区域显示就应该是 文字可显示的 东西
- 综上所述 需要耐心的分析 response 和 header 信息去确定哪条请求是我们想要的
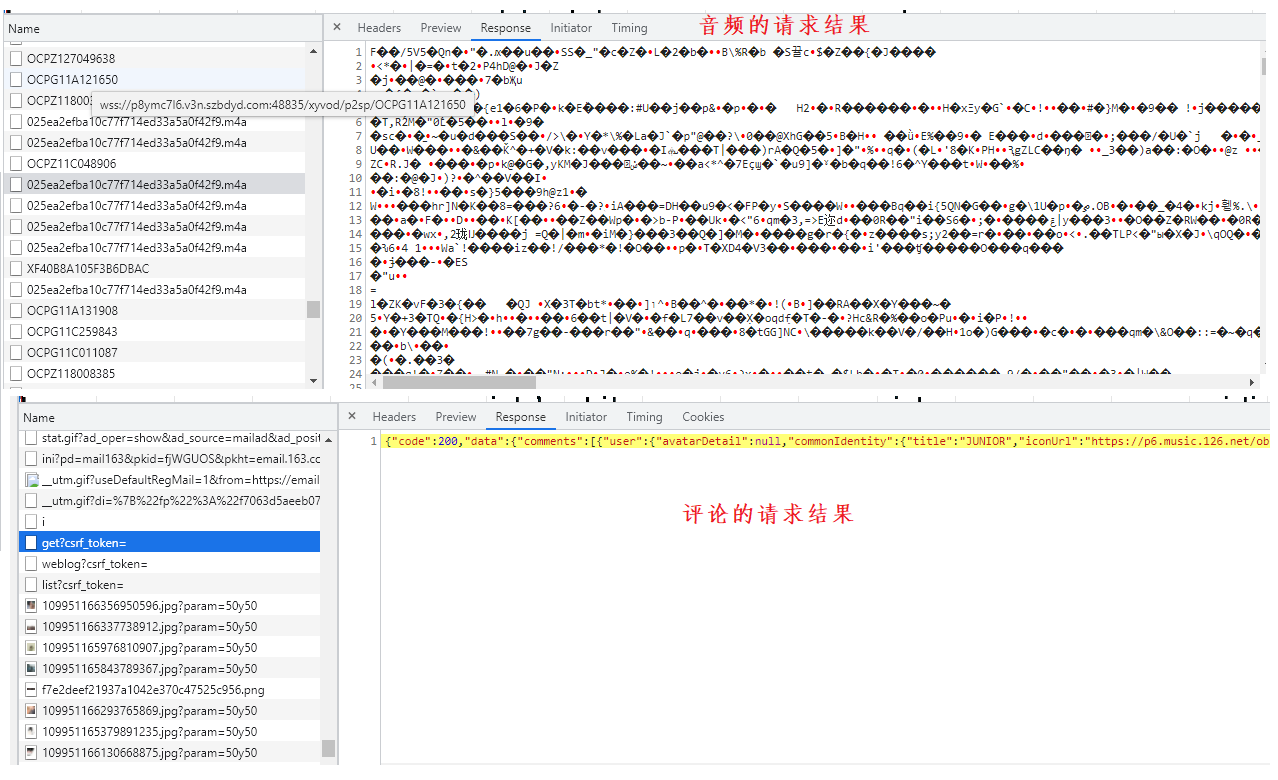
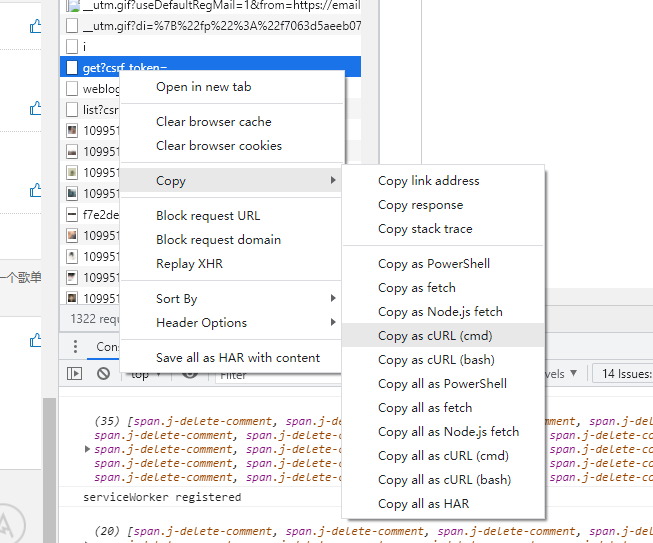
- 确定好目标请求后 就需要分析这条请求的 信息,然后使用 python 中的库 去模拟浏览器的行为 发送同样的请求即可。一个快捷的验证方法是,找到目标请求后 按照下述操作导出 cmd 然后粘贴到 这个链接 中可直接生成这条请求的 python 代码,直接测试。
- 分析查找条件下 请求 的变化规律。例如 查找第一页评论 和 第二页评论,发出的请求参数有什么变化,下载不同歌名的音频,发出的请求参数有什么变化。发现规律后就是使用 python 代码来实现这个变换规律,从而实现自动化爬取信息
- 成功拿到请求后就需要对 服务器响应的数据做分析,后续会有数据处理的方法
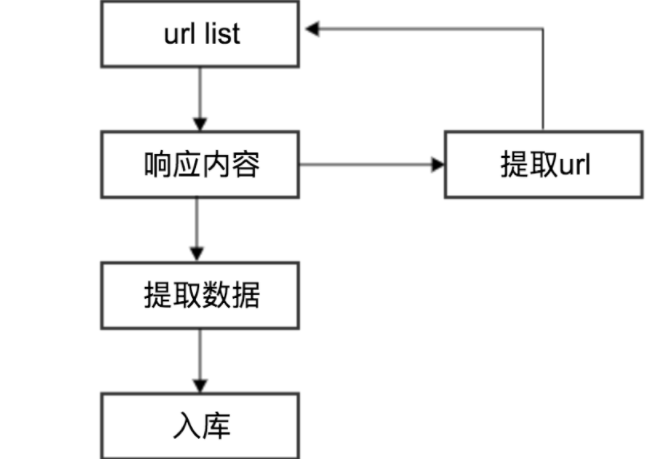
- 有的时候 可能不是 简单的 一次 请求 + 分析 就可以得到结果的。就需要下图中 从响应 结果中提取 url 再请求的流程
- 例如 (下载 b 站的视频,根据固定的 ip + 视频id 会有个固定的 url,但是下载m4a的视频缓冲文件 并不是这个url地址,而是需要先向这个url地址发送 一个请求,返回响应的数据中可能就包含了 下载视频的 url) 所以图中的流程中 有个提取 url 的步骤
request使用
1 | # 导入模块 |
使用代理服务器
让服务器认为不是同一个客户端在请求,防止被封 ip;防止真实地址被泄露,防止被追究
1 | # 导入模块 |
js逆向分析
服务端为了防止爬虫,有的会使用 js 混淆参数。本来是明文参数放在 请求里一起发送,但是这样很容易就被爬虫爬了,因此他们就将一些参数在浏览器端 通过 js 进行加密,然后将加密后的东西作为请求参数发送。这样一定程度上可以避免爬虫。但是很明显,由于 浏览器的 端的东西都是透明的,我们只需要逆向分析出 它 js 加密的地方就可以了。百度翻译中的逆向流程
基本的思路是:
找到 请求中加密的参数,例如下图中 的 params 和 encSecKey就是加密后的参数

然后在浏览器中全局搜索 encSecKey 这个关键字,找到这个数据生成的地方
然后在 js 文件中 加断点,并刷新浏览器 让它重新发送请求,断点调试观察变量,如下图就可以看到加密前的数据是啥(歌词的页数和偏移)
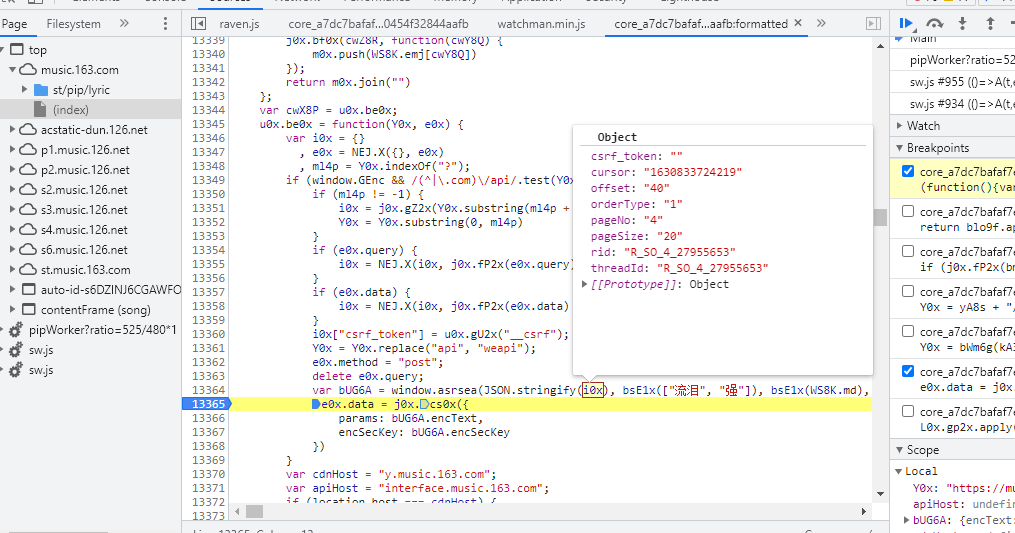
通过 断点调试/栈 去逐步逆向找到参数变化的规律 和 加密的函数 。然后在python中用代码实现相同的加密过程。这个调试需要有耐性。网易云的加密函数 是用的别人开源的 python版本的AES加密库,百度翻译的加密就是通过 js 函数实现的,可以直接把这个js函数拷贝出来,然后使用 python的 js2py 去执行 js 文件。
JS 逆向流程
- 通过关键词切入到代码中,切入到发送请求的代码行,通过请求的url中提取关键字
- 在发送请求的代码添加断点,并且触发发送请求,确认寻找的代码是否正确
- 往上逆向,寻找目标参数以及生成逻辑
- 利用js2py模拟执行生成逻辑获取想要的内容
chrome 调试技巧
- search 打开查询面板
- 查询面板可以通过关键字查找所有出现关键字地方的代码
- 点击跟踪代码并且可以把代码格式化
- 对格式化的代码进行设置断点
- 鼠标光标移动到上面可以查看当前运行代码变量值,函数原始代码地方等等
数据处理
大概的数据类型 有 json html 等格式,其实都有对应的库可以处理
json格式的响应:可以直接转换为 字典html格式的数据(即响应的是个网页):beautifulsoup库,正则表达式xml格式的数据:
实例代码
- 爬取b站的视频
- 爬取网易云的歌词和评论
- 百度翻译