动态场景、视频增强复原
动态场景HDR
早期的算法有将所有图象像素强度大概对齐到一定水平,然后使用光流算法完成图象空间对齐,最后再融合输出, 也有使用CNN实现光流的但是本质都是在图象层面完成了空间对齐。这篇文章作者将HDR看作图象到图象的转换,认为CNN有容忍偏差的能力,不需要显式的对齐图片,因此全用一个网络完成。
Deep HDR Reconstruction of Dynamic Scenes 这篇文章就是使用CNN在图象层面完成对齐,再使用CNN对对齐后的图象融合
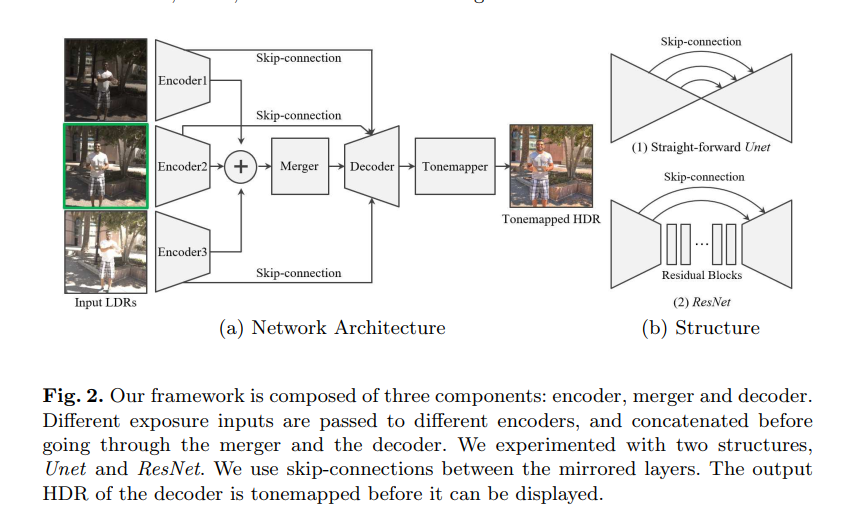
HDR-GAN: HDR Image Reconstruction from Multi-Exposed LDR Images with Large Motions
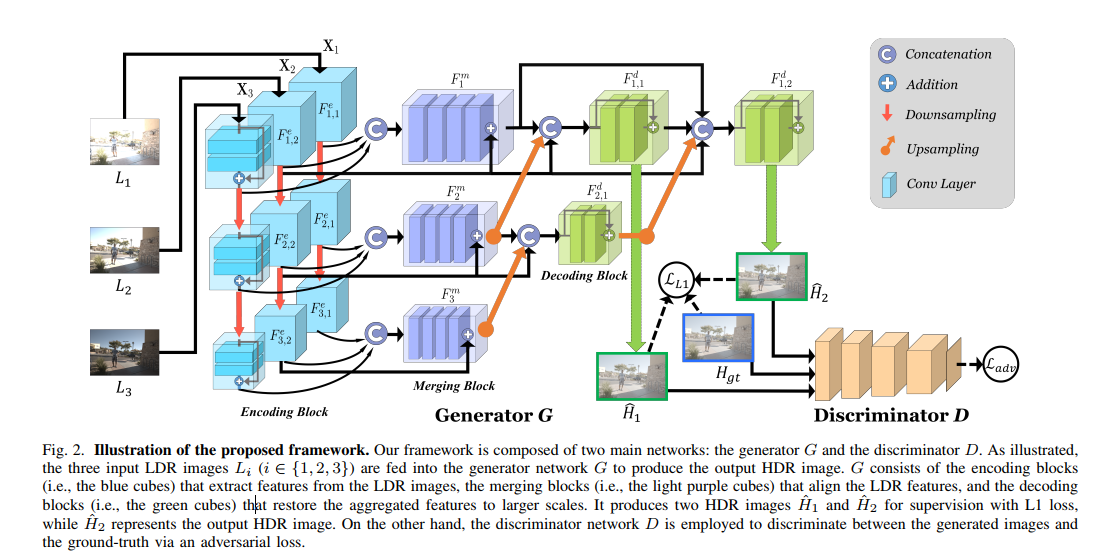
感觉这个文章和上面一篇区别不大,就是引入了GAN 他还是需要参考图的(图中的L1损失)。只不过生成器结构更复杂了。使用了多尺度的结果,左边浅蓝色是下采样的过程。文章还提到 最中间那个 + 连接 是有特征对齐的作用(浅紫色块处的+连接)。
### 视频重建
EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
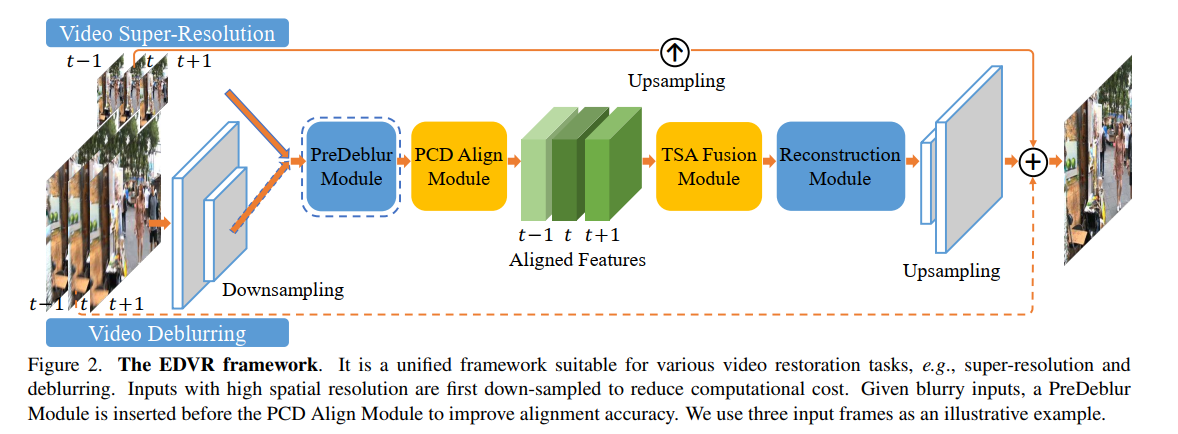
主体结构如上图。主要流程为 ->输入特征提取 --> 特征对齐模块 -> 特征融合模块 -> 重建输出。核心是特征对齐模块和融合模块。
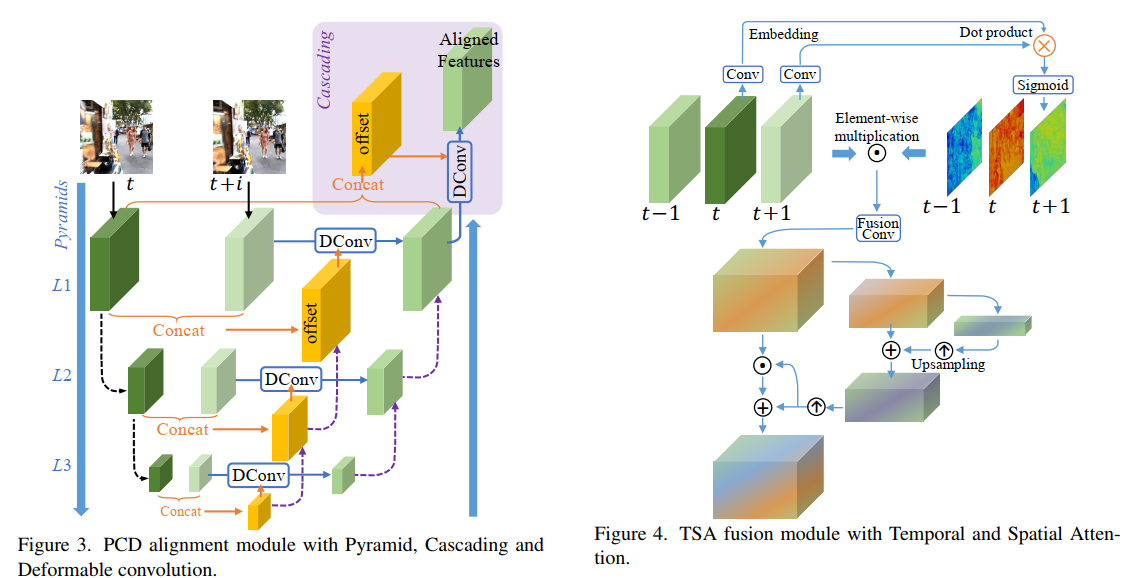
特征对齐模块的设计使用了可变性卷积 和 特征金子塔的结构。如下图。特征融合模块的一个重要的设计是 作者考虑到不同帧间即便对齐了,但是由于信息量的差异,应该有不同的权重,因此加入了注意力。
应该是端到端损失 据说不好训练
动态场景去噪
Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
这篇文章和上面那篇很相似。特征对准的方式几乎一样。只不过多了一个非局部模块。整个流程对去噪任务做了特定的设计。
视频去模糊
Spatio-Temporal Filter Adaptive Network for Video Deblurring
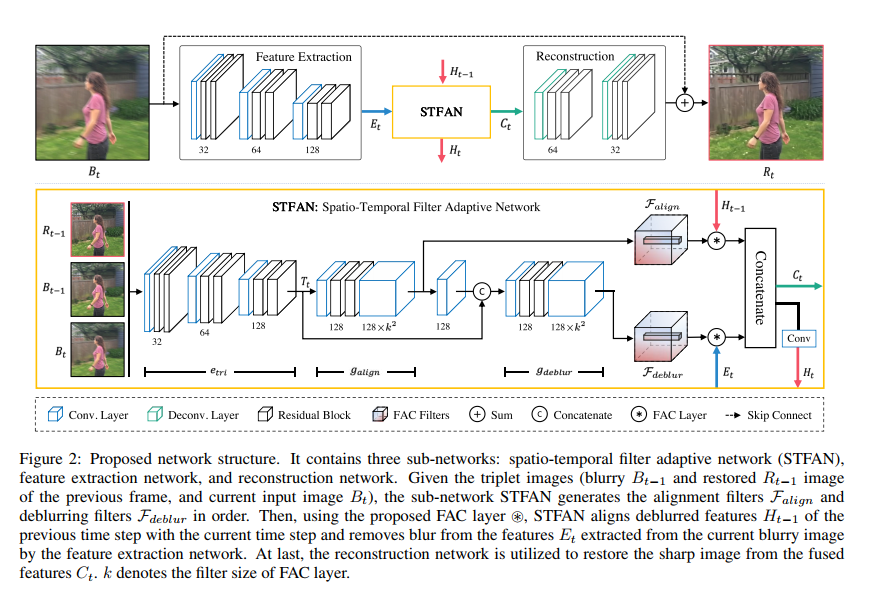
这篇文章视频去模糊的结构分为了三个模块 特征提取模块、STFAN模块、重建模块。可以看出,这篇文章的空间对齐和去模糊操作也都是在中间的特征空间完成的。但是这个STFAN模块采用了不同与可变性卷积的特征对齐方式。不过和上面的类似,他们都是采用了隐式的空间对齐方法,即网络中集成了可以完成空间对齐的结构,但是 本质上的约束都是来自最后的端到端的监督损失。
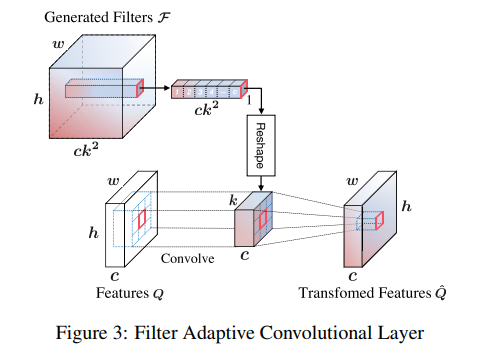
作者提出了一个 FAC layer 用于完成特征对齐和去模糊的操作。具体的流程:特征提取网络对当前帧提取特征得到Et STFAN模块则使用卷积对三元组输出处理得到 两个滤波器,一个是对齐滤波器一个是去模糊滤波器(图中的Falign deblur)。将估计的对齐滤波器(包含了复杂的运动参数)和上次迭代的 Ht-1(应该就是代表上一帧的去模糊后的特征图) 通过 FAC层得到一个对齐后的特征,同理去模糊滤波器也这么用。最后将两个特征concat(concat特征包含了这一帧去模糊的结果和上一帧去模糊后的特征图经过对齐后的结果)。 使用另一个解码器得到输出,同时concat的结果会传递到下一帧的计算。
FAC 层
很直观 这个为啥可以对其特征?
损失函数
也是很简单 一个MSE 一个感知损失